링크
https://yozm.wishket.com/magazine/detail/1931/
확실히 알아두면 만사가 편해지는 머신러닝 10가지 알고리즘 | 요즘IT
실무에서 원활히 머신러닝으로 데이터를 분석하는 데 얼마나 많은 알고리즘을 알고 있어야 할까요? 선형, 군집, 트리 같은 기본 개념을 알고 XGBoost와 LightGBM 같은 최신 알고리즘을 알면 우선 현
yozm.wishket.com
요약
1. 선형 회귀(Linear Regression)
- 목적: 연속형 변수인 목표 변수를 예측
- 몸무게, 나이, BMI, 성별 등의 데이터 활용
- 예측할 종속변수만 연속형 변수면 OK
- 데이터 특성이 복잡하지 않을 때는 쉽고 빠른 예측이 가능
- 구분: 지도학습
- 문제 유형: 회귀
- 적합한 데이터 유형: 종속변수와 독립변수가 선형 관계에 있는 데이터

- 장점
- 모델이 간단하기 때문에 구현과 해석이 쉽다
- 모델링 시간이 짧다
- 단점
- 최신 알고리즘에 비해 예측력이 떨어진다
- 독립변수와 예측변수의 선형 관계를 전제
2. 로지스틱 회귀(Logistic Regression)
- 선형 회귀 분석은 연속된 변수를 예측하는 반면, 로지스틱 회귀 분석은 Yes/No처럼 두 가지로 나뉘는 분류 문제를 다룬다.
- 이진 분류가 필요한 상황에서 두 가지 범주를 구분하는 간단한 예측에 유용
구분 : 지도 학습
문제 유형 : 분류적합한
데이터 유형 : 종속변수와 독립변수가 선형 관계에 있는 데이터

- 장점
- 선형 회귀 분석만큼 구현하기 용이하다
- 계수(기울기)를 사용해 각 변수의 중요성을 쉽게 파악할 수 있다
- 단점
- 선형 회귀 분석을 근간으로 하기 때문에, 선형 관계가 아닌 데이터에 대한 예측력이 떨어진다.
- 유용성
- Yes/No, True/False와 같은 두 가지 범주로 나뉜 값을 예측하는 데 사용
- 분류 문제에 있어서 기준선Baseline으로 자주 활용(타 모델과 비교 목적)
3. K-최근점 이웃(KNN, K Nearest Neighbors)
- 거리 기반 모델: 각 데이터 간의 거리를 활용해서 새로운 데이터를 예측, 가까이에 있는 데이터를 고려하여 예측값 결정
- 선형 관계를 전제로 하지 않는다
- K개의 가장 가까운 이웃 데이터에 의해 예측
- 다중분류 문제에 가장 간편히 적용할 수 있는 알고리즘
- 데이터가 크지 않고 예측이 까다롭지 않은 상황에서 KNN을 사용하면 신속하고 쉽게 예측 모델을 구현
구분 : 지도 학습
문제 유형 : 회귀/분류
적합한 데이터 유형 : 아웃라이어가 적은 데이터

- 장점
- 직관적이고 간단
- 선형 모델과 다르게 별도의 가정이 없다
- 단점
- 데이터가 커질수록 상당히 느려 다.
- 아웃라이어에 취약
- 유용성
- 주로 분류(Classification)에서 사용
- 로지스틱 회귀(Logistic Regression)로 해결할 수 없는 3개 이상의 목표 변수들도 분류
- 작은 데이터셋에 적합
4. 나이브 베이즈(Naive Bayes)
- 베이즈 정리를 적용한 조건부 확률 기반의 분류 모델
- 조건부 확률은 A가 일어났을 때 B가 일어날 확률
- 스팸 필터링을 위한 대표적인 모델
- 범용성이 높지는 않지만 독립변수들이 모두 독립적이라면 충분히 경쟁력이 있는 알고리즘
- 딥러닝을 제외하고 자연어 처리에 가장 적합한 알고리즘
구분 : 지도 학습
문제 유형 : 분류
적합한 데이터 유형 : 독립변수의 종류가 매우 많은 경우

- 장점
- 비교적 간단한 알고리즘에 속하며 속도 또한 빠르다.
- 작은 훈련셋으로도 예측 가능
- 단점
- 모든 독립변수가 각각 독립적임을 전제로 하는데 이는 장점이며 단점. 실제로 독립변수들이 모두 독립적이라면 다른 알고리즘보다 우수할 수 있지만, 실제 데이터에서 그런 경우가 많지 않다
- 유용성
- 각 독립변수들이 모두 독립적이고 그 중요도가 비슷할 때 유용.
- 자연어 처리(NLP)에서 간단하지만 좋은 성능을 보여준다.
- 범주 형태의 변수가 많을 때 적합하며, 숫자형 변수가 많을 때는 적합하지 않다.
5. 결정 트리(Decision Tree)
- 관측값과 목푯값을 연결시켜주는 예측 모델로서 나무 모양으로 데이터를 분류
- 선형 모델이 각 변수에 대한 기울기값들을 최적화하여 모델을 만들어나갔다면, 트리 모델에서는 각 변수의 특정 지점을 기준으로 데이터를 분류해가며 예측 모델을 만든다
- 예를 들어 남자/여자로 나눠서 각 목푯값 평균치를 나눈다거나, 나이를 30세 이상/미만인 두 부류로 나눠서 평균치를 계산하는 방식으로 데이터를 무수하게 쪼개어나가고, 각 그룹에 대한 예측치를 만들어낸다
- 다른 트리 기반 모델을 설명하려면 결정 트리를 알아야 한다
구분 : 지도 학습
문제 유형 : 회귀/분류
적합한 데이터 유형 : 일반적인 데이터

- 장점
- 데이터에 대한 가정이 없는 모델(Non-parametric Model)
- 데이터에 대한 가정이 없으므로 어디에나 자유롭게 적용
- 아웃라이어에 영향을 거의 받지 않는다.
- 트리 그래프를 통해서 직관적으로 이해하고 설명할 수 있다. 즉 시각화에 탁월
- 단점
- 트리가 무한정 깊어지면 오버피팅 문제를 야기
- 앞으로 배울 발전된 트리 기반 모델들에 비하면 예측력이 떨어진다.
- 유용성
- 종속변수가 연속형 데이터와 범주형 데이터 모두에 사용
- 모델링 결과를 시각화할 목적으로 가장 유용
- 아웃라이어가 문제될 정도로 많을 때 선형 모델보다 좋은 대안
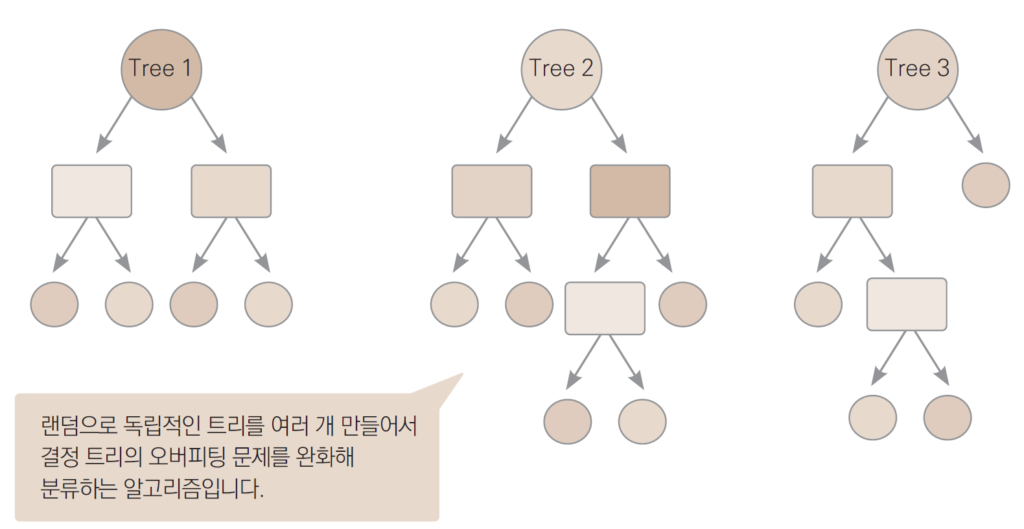
6. 랜덤 포레스트(Random Forest)
- 결정 트리의 단점인 오버피팅 문제를 완화시켜주는 발전된 형태의 트리 모델
- 각 트리를 독립적으로 만드는 알고리즘
- 랜덤으로 생성된 무수히 많은 트리(여러 모델)를 이용하여 예측
- 여러 모델(여기서는 결정 트리)을 활용하여 하나의 모델을 이루는 기법을 앙상블
- 앙상블 기법을 사용한 트리 기반 모델 중 가장 보편적인 방법
구분 : 지도 학습
문제 유형 : 회귀/분류
적합한 데이터 유형 : 일반적인 데이터
- 장점
- 결정 트리와 마찬가지로, 아웃라이어에 거의 영향을 받지 않는다.
- 선형/비선형 데이터에 상관없이 작동
- 단점
- 학습 속도가 상대적으로 느린 편
- 수많은 트리를 동원하기 때문에 모델에 대한 해석이 어렵다.
- 유용성
- 다음 단계인 부스팅 모델을 이해하려면 꼭 알아야 할 필수 알고리즘
7. XG부스트(XGBoost)
- 부스팅은 순차적으로 트리를 만들어 이전 트리로부터 더 나은 트리를 만들어내는 알고리즘
- 랜덤 포레스트보다 훨씬 빠른 속도와 더 좋은 예측 능력 보유
- 대표적인 알고리즘으로 XG부스트(eXtra Gradient Boost), 라이트GBM(LightGBM), 캣부스트(CatBoost) 등
- XGBoost는 손실함수뿐만 아니라 모형 복잡도까지 고려
- 구글 검색에서 수많은 참고 자료(활용 예시, 다양한 하이퍼파라미터 튜닝)를 쉽게 접할 수 있다.
구분 : 지도 학습
문제 유형 : 회귀/분류
적합한 데이터 유형 : 일반적인 데이터

- 장점
- 예측 속도가 상당히 빠르며, 예측력 또한 좋다.
- 변수 종류가 많고 데이터가 클수록 상대적으로 뛰어난 성능
- 단점
- 복잡한 모델인 만큼, 해석에 어려움이 있다.
- 더 나은 성능을 위한 하이퍼파라미터 튜닝이 까다롭다.
8. 라이트GBM(LightGBM)
- LightGBM이 등장하기 전까지는 XGBoost가 가장 인기있는 부스팅 모델이였지만, 점점 LightGBM이 XGBoost와 비슷한 수준 혹은 그 이상으로 활용되는 추세
- 리프 중심 트리 분할 방식을 사용
- 표로 정리된 데이터(tabular data)에서 Catboost, XGBoost와 함께 가장 좋은 성능을 보여주는 알고리즘
구분 : 지도 학습
문제 유형 : 회귀/분류
적합한 데이터 유형 : 일반적인 데이터

- 장점
- XGBoost보다도 빠르고 높은 정확도를 보여주는 경우가 많다.
- 예측에 영향을 미친 변수의 중요도를 확인할 수 있다.
- 변수 종류가 많고 데이터가 클수록 상대적으로 뛰어난 성능을 보여준다.
- 단점
- 복잡한 모델인 만큼, 해석에 어려움이 있다.
- 하이퍼파라미터 튜닝이 까다롭다.
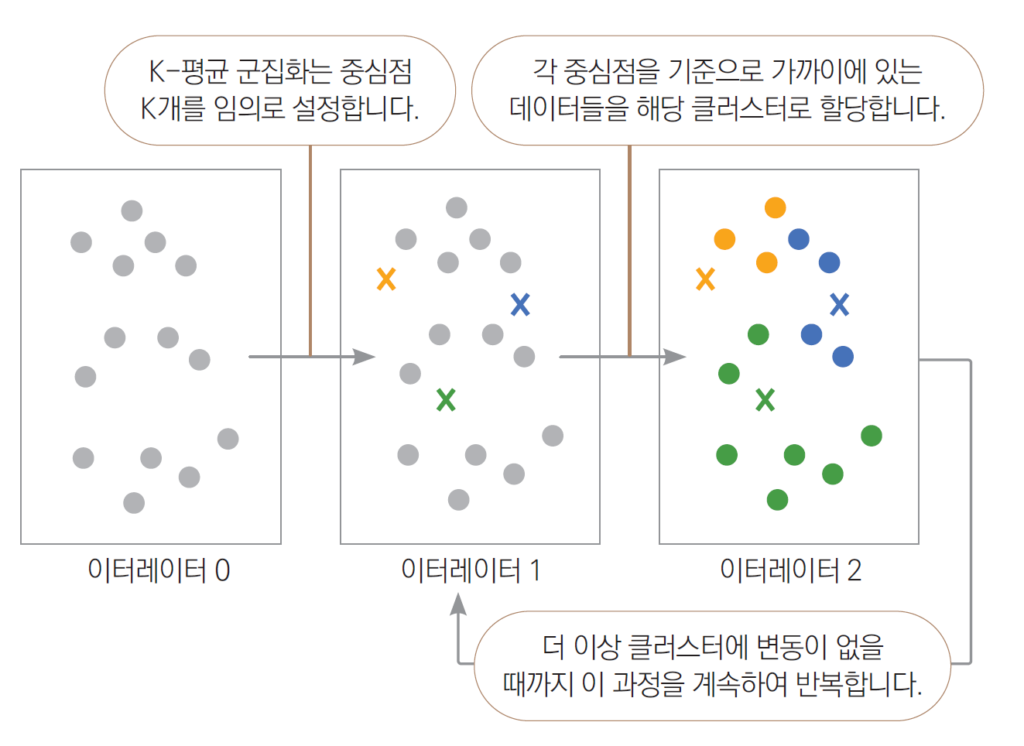
9. K-평균 군집화(K Means Clustering)
- 비지도 학습의 대표적인 알고리즘
- 목표 변수가 없는 상태에서 데이터를 비슷한 유형끼리 묶어내는 머신러닝 기법
- K-최근접 이웃 알고리즘과 비슷하게 거리 기반으로 작동하며 적절한 K값을 사용자가 지정
- 거리 기반으로 작동하기 때문에 데이터 위치가 가까운 데이터끼리 한 그룹으로 묶는다
- 이때 전체 그룹의 수는 사용자가 지정한 K개
- 데이터를 적절한 수의 그룹으로 나누고 그 특징을 살펴볼 수 있는 장점을 제공
구분 : 비지도 학습
- 장점
- 구현이 비교적 간단.
- 클러스터링 결과를 쉽게 해석
- 단점
- 최적의 K값을 자동으로 찾지 못하고, 사용자가 직접 선택
- 거리 기반 알고리즘이기 때문에, 변수의 스케일에 따라 다른 결과를 나타낸다
10. 주성분 분석(PCA)
- PCA는 Principal Component Analysis의 약자로, 주성분 분석
- 비지도 학습에 속하기 때문에 당연히 종속 변수는 존재하지 않는다.
- 어떤 것을 예측하지도 분류하지도 않는다
- PCA의 목적: 데이터의 차원을 축소
- 차원 축소를 간단히 말하면 변수의 개수를 줄이되, 가능한 그 특성을 보존해내는 기법
- 기존 변수들의 정보를 모두 반영하는 새로운 변수들을 만드는 방식으로 차원 축소
- 차원 축소를 시도해봄으로써 시각화 내지 모델링 효율성을 개선할 여지는 항상 있다.
구분: 비지도 학습

- 장점
- 다차원을 2차원에 적합하도록 차원 축소하여 시각화에 유용.
- 변수 간의 높은 상관관계 문제를 해결.
- 단점
- 기존 변수가 아닌 새로운 변수를 사용하여 해석하는 데 어려움.
- 차원이 축소됨에 따라 정보 손실이 불가피
- 유용성
- 다차원 변수들을 2차원 그래프로 표현하는 데 사용
- 변수가 너무 많아 모델 학습에 시간이 너무 오래 걸릴 때 (차원 축소를 진행하면 학습에 드는 시간을 줄일 수 있어) 유용.
- 오버피팅을 방지하는 용도로 사용
주요 포인트
- 선형, 군집, 트리와 같은 기본 개념
- XGBoost와 LightGBM 같은 최신 알고리즘
- 추가 공부는 논문 등을 이용해 지속 학습
핵심 개념
- 머신러닝은 컴퓨터가 명시적으로 프로그래밍되지 않고도 데이터를 통해 학습하고 예측을 수행할 수 있도록 하는 기술. 이는 인공지능(AI)의 하위 분야로, 컴퓨터가 대량의 데이터를 분석하여 패턴을 인식하고, 이를 기반으로 결정을 내리거나 예측을 수행하는 데 중점
용어 정리
- BMI(Body Mass Index): 키와 체중으로 계산한 대략적인 체질량지수
실무 적용 사례

'[직무 이해] > 칼럼' 카테고리의 다른 글
| [거래 후기 실험을 통해 따뜻한 거래 경험 만들기]를 읽고 (0) | 2024.11.15 |
|---|---|
| [알라미의 A/B 테스팅 일지 #1]를 읽고 (2) | 2024.11.13 |
| 더 나은 대시보드 디자인을 위한 10개명: 10 rules for better dashboard design (0) | 2024.10.25 |
| [데이터 시각화 101: ③데이터 속 거짓말 발견하기]를 읽고 (0) | 2024.10.22 |
| [데이터 시각화 101: ②직관적인 데이터 시각화 만들기]를 읽고 (0) | 2024.10.17 |


