제1절 서브 쿼리
1. 아래에서 설명하는 서브쿼리의 종류로 가장 적절한 것은?
서브쿼리의 실행 결과로 여러 칼럼을 반환한다. 메인쿼리의 조건절에 여러 칼럼을 동시에 비교할 수 있다. 서브쿼리와 메인쿼리에서 비교하고자 하는 칼럼 개수와 칼럼의 위치가 동일해야 한다.
- 단일 행(Single Row) 서브쿼리
- 다중 칼럼(Multi Column) 서브쿼리
- 다중 행(Multi Row) 서브쿼리
- 단일 칼럼(Single Column) 서브쿼리
문제에 필요한 개념 설명: 서브쿼리의 종류
서브쿼리는 SQL에서 메인 쿼리 내부에 포함된 쿼리를 의미하며, 다양한 방식으로 데이터를 처리하거나 조건을 제공하는 데 사용됩니다. 서브쿼리는 반환하는 데이터의 형태에 따라 다음과 같은 종류로 나뉩니다:
1. 단일 행(Single Row) 서브쿼리: 하나의 행과 하나의 값을 반환합니다. 주로 `=`, `<`, `>` 등의 연산자와 함께 사용됩니다.
2. 단일 칼럼(Single Column) 서브쿼리: 하나의 칼럼과 여러 행을 반환합니다. 주로 `IN`, `ANY`, `ALL` 연산자와 함께 사용됩니다.
3. 다중 행(Multi Row) 서브쿼리: 여러 행을 반환하며, 특정 조건에 따라 메인 쿼리와 비교됩니다.
4. 다중 칼럼(Multi Column) 서브쿼리: 여러 칼럼과 여러 행을 반환하며, 메인 쿼리에서 여러 칼럼을 동시에 비교할 때 사용됩니다.
[예시]
SELECT emp_id, emp_name
FROM employee
WHERE (dept_id, salary) IN (
SELECT dept_id, MAX(salary)
FROM employee
GROUP BY dept_id
);
2. SQL 실행 결과가 다른 하나는?
1.
SELECT COL1, SUM(COL2)
FROM T1
GROUP BY COL1
UNION ALL
SELECT NULL, SUM(COL2)
FROM T1
ORDER BY 1 ASC;
2.
SELECT COL1, SUM(COL2)
FROM T1
GROUP BY GROUPING SETS (COL1)
ORDER BY 1 ASC;
3.
SELECT COL1, SUM(COL2)
FROM T1
GROUP BY ROLLUP (COL1)
ORDER BY 1 ASC;
4.
SELECT COL1, SUM(COL2)
FROM T1
GROUP BY CUBE (COL1)
ORDER BY 1 ASC;1. ROLLUP:
• `GROUP BY ROLLUP`은 지정된 컬럼 순서에 따라 단계별 소계와 총계를 계산합니다.
• 예를 들어, `GROUP BY ROLLUP(A, B)`는 다음과 같은 그룹을 생성합니다:
1. `(A, B)`
2. `(A)`
3. `() (총계)`
2. CUBE:
• `GROUP BY CUBE`는 지정된 모든 컬럼의 가능한 모든 조합에 대해 소계와 총계를 계산합니다.
• 예를 들어, `GROUP BY CUBE(A, B)`는 다음과 같은 그룹을 생성합니다:
1. `(A, B)`
2. `(A)`
3. `(B)`
4. `() (총계)`
3. GROUPING SETS:
• `GROUPING SETS`는 특정 그룹을 명시적으로 정의하여 집계를 수행합니다.
• 예를 들어, `GROUP BY GROUPING SETS((A), (B), ())`는 명시된 그룹만 계산하며, 다른 조합은 포함하지 않습니다.
4. UNION ALL:
• 여러 쿼리의 결과를 합쳐 하나의 결과로 반환합니다. 중복된 행도 포함됩니다.
• `ROLLUP`, `CUBE`, `GROUPING SETS`는 내부적으로 `UNION ALL`과 유사한 방식으로 작동하지만 더 효율적입니다.
제2절 집합 연산자
1. 집합 연산자에 대한 설명으로 가장 적절하지 않은 것은?
- UNION 연산자는 합집합 결과에서 중복된 행을 하나의 행으로 만든다.
- UNION ALL 연산자는 집합 간의 결과가 중복되지 않는 경우, UNION과 결과가 동일하다.
- UNION 연산자를 사용한 SQL은 각각의 집합에 GROUP BY절을 사용할 수 있다.
- UNION 연산자를 사용한 SQL은 각각의 집합에 ORDER BY절을 사용할 수 있다.
집합 연산자 개념 정리
1. UNION:
• 두 SELECT 문 결과를 합집합으로 반환하며, 중복된 행은 제거됩니다.
• 반환된 결과는 기본적으로 정렬되어 출력됩니다(정렬 기준은 내부적으로 처리).
2. UNION ALL:
• 두 SELECT 문 결과를 합집합으로 반환하며, 중복된 행도 그대로 포함합니다.
• 정렬은 수행되지 않으며, 결과는 입력 순서대로 반환됩니다.
3. GROUP BY와 ORDER BY:
• `GROUP BY`는 각 SELECT 문 내부에서 사용할 수 있습니다.
• `ORDER BY`는 전체 UNION 결과에 대해 한 번만 사용할 수 있습니다. 개별 SELECT 문에서 `ORDER BY`를 사용하는 것은 허용되지 않습니다.
문항 분석
1. “UNION 연산자는 합집합 결과에서 중복된 행을 하나의 행으로 만든다.”
• UNION은 중복된 행을 제거하여 고유한 값만 반환합니다.
2. “UNION ALL 연산자는 집합 간의 결과가 중복되지 않는 경우, UNION과 결과가 동일하다.”
• 두 SELECT 문에서 중복된 데이터가 없으면 UNION과 UNION ALL의 결과는 동일합니다.
3. “UNION 연산자를 사용한 SQL은 각각의 집합에 GROUP BY절을 사용할 수 있다.”
• 각 SELECT 문 내부에서는 독립적으로 `GROUP BY`를 사용할 수 있습니다.
4. “UNION 연산자를 사용한 SQL은 각각의 집합에 ORDER BY절을 사용할 수 있다.”
• `ORDER BY`는 전체 UNION 결과에 대해서만 사용할 수 있으며, 개별 SELECT 문에서는 사용할 수 없습니다
제3절 그룹 함수
1. 아래에서 서브쿼리에 대한 설명으로 적절한 것을 모두 고른 것은?
(가) 서브쿼리는 단일 행(Single Row) 또는 복수 행(Multi Row) 비교 연산자와 함께 사용할 수 있다.
(나) 서브쿼리는 SELCT 절, FROM 절, HAVING 절, ORDER BY 절 등에서 사용이 가능하다.
(다) 서브쿼리의 결과가 복수 행(Multi Row) 결과를 반환하는 경우에는 '=', '<=', '=>' 등의 연산자와 함께 사용할 수 있다.
(라) 연관(Correlated) 서브쿼리는 서브쿼리가 메인쿼리 칼럼을 포함하고 있는 형태의 서브쿼리이다.
(마) 다중 칼럼 서브쿼리는 서브쿼리의 결과로 여러 개의 칼럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미하며 오라클 및 SQL Server 등의 DMBS에서 사용할 수 있다.
(가) “서브쿼리는 단일 행(Single Row) 또는 복수 행(Multi Row) 비교 연산자와 함께 사용할 수 있다.”
• 서브쿼리는 단일 행 결과를 반환하는 경우 `=`, `<`, `>` 등의 연산자와 함께 사용됩니다.
• 복수 행 결과를 반환하는 경우에는 `IN`, `ANY`, `ALL` 등의 연산자와 함께 사용해야 합니다.
• 적절성: 적절함.
• 단일 행/복수 행 비교 연산자 모두 서브쿼리에서 사용 가능합니다.
(나) “서브쿼리는 SELECT 절, FROM 절, HAVING 절, ORDER BY 절 등에서 사용이 가능하다.”
• 서브쿼리는 일반적으로 SELECT, FROM, WHERE, HAVING 절에서 사용됩니다.
• ORDER BY 절에서는 서브쿼리를 사용할 수 없습니다라는 것이 일반적인 오해입니다. 그러나 실제로 ORDER BY 절에서도 서브쿼리를 사용할 수 있습니다. 예를 들어, 다음과 같은 쿼리가 가능합니다:
(다) “서브쿼리의 결과가 복수 행(Multi Row) 결과를 반환하는 경우에는 ‘=’, ‘<=’, ‘=>’ 등의 연산자와 함께 사용할 수 있다.”
• 복수 행 결과를 반환하는 서브쿼리는 `IN`, `ANY`, `ALL`과 같은 연산자를 사용해야 하며, 단일 값만 반환될 때만 `=` 또는 `<` 등의 연산자를 사용할 수 있습니다.
• 적절성: 부적절함.
• 복수 행 결과를 반환하는 경우에는 ‘=’, ‘<=’, ’=>’와 같은 연산자를 사용할 수 없습니다.
(라) “연관(Correlated) 서브쿼리는 서브쿼리가 메인 쿼리 칼럼을 포함하고 있는 형태의 서브쿼리이다.”
• 연관 서브쿼리는 메인 쿼리의 칼럼 값을 참조하여 동적으로 실행되는 서브쿼리입니다. 메인 쿼리의 각 행에 대해 서브쿼리가 반복적으로 실행됩니다.
(마) “다중 칼럼 서브쿼리는 서브쿼리의 결과로 여러 개의 칼럼이 반환되어 메인 쿼리의 조건과 동시에 비교되는 것을 의미하며 오라클 및 SQL Server 등의 DBMS에서 사용할 수 있다.”
• 다중 칼럼 서브쿼리는 `(칼럼1, 칼럼2)`와 같은 형식으로 여러 칼럼을 반환하며, 메인 쿼리에서 여러 칼럼을 동시에 비교할 때 사용됩니다. SQL server에서는 현재 지원하지 않는 기능이다.
2. 서브쿼리에 대한 설명으로 가장 적절한 것은?
- 단일 행 서브쿼리는 서브쿼리의 실행 결과가 항상 한 건 이하인 서브쿼리로 IN, ALL 등의 비교 연산자를 사용하여야 한다.
- 다중 행 서브쿼리 비교 연산자는 단일 행 서브쿼리의 비교 연산자로도 사용할 수 있다.
- 연관 서브쿼리는 주로 메인쿼리에 값을 제공하기 위한 목적으로 사용한다.
- 서브 쿼리는 항상 메인쿼리에서 읽힌 데이터에 대해 서브쿼리에서 해당 조건이 만족하는지를 확인하는 방식으로 수행된다.
1. 단일 행 서브쿼리의 비교 연산자로는 =, <, <=, >, >=, <>가 되어야 한다. IN, ALL 등의 비교 연산자는 다중 행 서브쿼리의 비교연산자이다.
2. 단일 행 서브쿼리의 비교연산자는 다중 행 서브쿼리의 비교 연산자로 사용할 수 없지만, 반대의 경우는 가능하다.
3. 비 연관 서브쿼리가 주로 메인쿼리에 값을 제공하기 위한 목적으로 사용된다.
4. 메인쿼리의 결과가 서브쿼리로 제공될 수도 있고, 서브쿼리의 결과가 메인쿼리로 제공될 수도 있으므로 실행 순서는 상황에 따라 달라진다.
3. 아래 SQL에 대한 설명으로 가장 적절하지 않은 것은?
SELECT B.사원번호, B.사원명, A.부서번호, A.부서명
FROM 부서 A, (SELECT *
FROM 사원
WHERE 입사년도 = '2014') B
WHERE A.부서번호 = B.부서번호
AND EXISTS (SELECT 1
FROM 사원 X
WHERE X.부서번호 = A.부서번호);- 위 SQL에는 다중 행 연관 서브쿼리, 단일 행 연관 서브쿼리, 인라인뷰가 사용되었다.
- SELECT 절에 사용된 서브쿼리는 스칼라 서브쿼리라고도 하며, 이러한 형태의 서브쿼리는 JOIN으로 동일한 결과를 추출할 수도 있다.
- WHERE 절의 서브쿼리에 사원 테이블 검색 조건으로 입사년도 조건을 FROM절의 서브쿼리와 동일하게 추가해야 원하는 결과를 추출할 수 있다.
- FROM절의 서브쿼리는 동적 뷰(Dynamic View)라고도 하며, SQL 문장 중 테이블 명이 올 수 있는 곳에서 사용할 수 있다.
Select 절에 사용된 서브쿼리는 단일행 연관 서브쿼리로 JOIN으로도 변경이 가능하며, FROM 절에 사용된 서브쿼리는 Inline View 또는 Dynamic View이고, WHERE 절에 사용된 서브쿼리는 다중행 연관 서브쿼리이다. 3번 보기의 경우 이미 FROM 절에 Inline View로 사원 테이블의 입사년도 조건을 명시하였으므로 WHERE 절의 EXISTS 조건은 부서와 사원 테이블 간의 JOIN 조건에 의해 결과에 어떠한 영향도 미치지 못하므로 삭제되어도 무방하다.
4. 뷰에 대한 설명으로 가장 적절하지 않은 것은?
- 뷰는 단지 정의만을 가지고 있으며, 실행 시점에 질의를 재작성하여 수행한다.
- 뷰는 복잡한 SQL 문장을 단순화하는 장점이 있는 반면, 테이블 구조가 변경되면 응용 프로그램을 변경해 주어야 한다.
- 뷰는 보안을 강화하기 위한 목적으로도 활용할 수 있다.
- 실제 데이터를 저장하고 있는 뷰를 생성하는 기능을 지원하는 DBMS도 있다.
뷰(View)란?
• 뷰는 하나 이상의 테이블에서 데이터를 가져와 정의된 SQL 쿼리에 따라 생성된 가상 테이블입니다.
• 실제 데이터를 저장하지 않으며, 뷰는 저장된 SQL 정의를 기반으로 실행 시점에 데이터를 조회합니다.
• 뷰는 복잡한 SQL을 단순화하고, 보안 및 접근 제어를 강화하는 데 유용합니다.
- 독립성: 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다.
- 편리성: 복잡한 질의를 뷰로 생성하여 관련 질의를 단순하게 작성할 수 있다. 또한 해당 형태의 SQL을 자주 사용할 때 뷰를 이용하면 편리하게 사용할 수 있다.
- 보안성: 직원의 급여정보와 같이 숨기고 싶은 정보가 존재한다면, 뷰를 생성할 때 해당 칼럼을 빼고 생성하여 사용자에게 정보를 감출 수 있다.
1. “뷰는 단지 정의만을 가지고 있으며, 실행 시점에 질의를 재작성하여 수행한다.”
• 일반적인 뷰는 데이터를 저장하지 않고, SQL 정의만을 저장합니다.
• 실행 시점에 뷰의 정의를 기반으로 질의가 재작성되어 수행됩니다.
2. “뷰는 복잡한 SQL 문장을 단순화하는 장점이 있는 반면, 테이블 구조가 변경되면 응용 프로그램을 변경해 주어야 한다.”
• 뷰는 복잡한 SQL 문장을 단순화하여 재사용성을 높이는 장점이 있습니다.
• 하지만 이 진술에서 “테이블 구조가 변경되면 응용 프로그램을 변경해 주어야 한다”는 부분은 부정확합니다.
• 테이블 구조가 변경되더라도 뷰가 정상적으로 작동하는 경우가 많습니다(예: 테이블에 새로운 컬럼 추가).
• 다만, 뷰가 의존하는 테이블의 기존 컬럼 삭제 또는 이름 변경과 같은 경우에만 뷰 정의를 수정해야 합니다.
• 따라서 “테이블 구조 변경 시 응용 프로그램을 반드시 변경해야 한다”는 과장된 표현으로, 항상 맞는 설명이 아닙니다.
3. “뷰는 보안을 강화하기 위한 목적으로도 활용할 수 있다.”
• 뷰는 특정 테이블의 일부 컬럼이나 행만 노출하도록 설정할 수 있어 보안을 강화하는 데 유용합니다.
• 예를 들어, 민감한 정보(예: 급여)를 제외하고 나머지 데이터를 제공하는 뷰를 생성할 수 있습니다.
• 이는 뷰의 주요 사용 사례 중 하나로 적절한 설명입니다.
4. “실제 데이터를 저장하고 있는 뷰를 생성하는 기능을 지원하는 DBMS도 있다.”
• 일반적인 뷰는 데이터를 저장하지 않으며, 실행 시점에 데이터를 조회합니다.
• 그러나 일부 DBMS(예: Oracle의 Materialized View 또는 SQL Server의 Indexed View)는 데이터를 저장하는 “특수한 형태의 뷰”를 지원합니다.
• 이 문장에서 “일반적인 뷰”와 “특수한 형태의 뷰(Materialized View)“를 구분하지 않고 설명했지만, 사실상 일부 DBMS에서 데이터를 저장하는 뷰를 지원하므로 이 설명은 기술적으로 맞습니다.
추가 학습 포인트
1. 뷰와 테이블 구조 변경 간의 관계:
• 테이블에 새로운 컬럼이 추가되거나 기존 컬럼이 삭제되지 않는 한, 대부분의 경우 뷰는 정상적으로 작동합니다.
• 그러나 의존하는 테이블의 기존 컬럼이 삭제되거나 이름이 변경되면, 해당 컬럼을 참조하는 뷰 정의를 수정해야 합니다.
2. 뷰의 장점:
• 복잡한 SQL 문장을 단순화하여 재사용성을 높임.
• 특정 데이터만 노출하여 보안을 강화함.
3. 뷰의 단점:
• 성능 저하 가능성(특히 복잡한 쿼리를 포함한 경우).
• 테이블 구조 변경 시 일부 수정이 필요할 수 있음.
5. 아래를 참고할 때 SQL의 빈칸 ㄱ에 들어갈 내용으로 가장 적절한 것은?
[SQL]
SELCT DNAME,
JOB,
COUNT(EMPNO) TOTAL_EMP,
SUM(SAL) TOTAL_SAL
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ㄱ
;
[실행 결과]
| DNAME | JOB | TOTAL_EMP | TOTAL_SAL |
| SALES | CLERK | 1 | 950 |
| SALES | MANAGER | 1 | 2850 |
| SALES | SALESMAN | 4 | 5600 |
| SALES | NULL | 6 | 9400 |
| RESEARCH | CLERK | 2 | 1900 |
| RESEARCH | ANALYST | 2 | 6000 |
| RESEARCH | MANAGER | 1 | 2975 |
| RESEARCH | NULL | 5 | 10875 |
| ACCOUNTING | CLERK | 1 | 1300 |
| ACCOUNTING | MANAGER | 1 | 2450 |
| ACCOUNTING | PRESIDENT | 1 | 5000 |
| ACCOUNTING | NULL | 3 | 8750 |
| NULL | NULL | 14 | 29025 |
결과에서 확인할 수 있는 사항
1. GROUP BY 기준:
• 결과는 `DNAME`(부서명)과 `JOB`(직업)별로 그룹화되어 있습니다.
• 따라서 `GROUP BY` 절에는 `DNAME`과 `JOB`이 포함되어야 합니다.
2. NULL 값 처리:
• `DNAME` 또는 `JOB`이 NULL인 경우도 포함되어 있습니다.
• 이는 SQL에서 GROUP BY가 NULL 값을 별도의 그룹으로 처리하기 때문입니다.
3. 전체 합계 행:
• 마지막 행에서는 `DNAME`과 `JOB`이 모두 NULL이며, 이는 전체 데이터를 하나의 그룹으로 묶은 결과로 보입니다.
• 하지만 이와 같은 “전체 합계”는 GROUP BY 절과 직접적인 관련은 없으며, 일반적으로 ROLLUP 또는 UNION 등을 통해 추가됩니다.
추가 학습 포인트
1. GROUP BY와 NULL 값 처리:
• SQL의 GROUP BY는 NULL 값을 별도의 그룹으로 처리합니다.
• 따라서 결과에서 `DNAME` 또는 `JOB`이 NULL인 경우에도 별도의 그룹으로 계산됩니다.
2. ROLLUP 사용:
• 전체 합계를 포함하려면 GROUP BY ROLLUP을 사용할 수 있습니다:
GROUP BY ROLLUP(DNAME, JOB)
6. 아래 SQL의 실행 결과로 가장 적절한 것은?
[월별매출]
| 상품ID | 월 | 매출액 |
| P001 | 2014.10 | 1500 |
| P001 | 2014.11 | 1500 |
| P001 | 2014.12 | 2500 |
| P002 | 2014.10 | 1000 |
| P002 | 2014.11 | 2000 |
| P002 | 2014.12 | 1500 |
| P003 | 2014.10 | 2000 |
| P003 | 2014.11 | 1000 |
| P003 | 2014.12 | 1000 |
[SQL]
SELECT 상품ID, 월, SUM(매출액) as 매출액
FROM 월별매출
WHERE 월 BETWEEN '2014.10' AND '2014.12'
GROUP BY GROUPING SETS((상품ID, 월));
주요 특징:
1. GROUPING SETS:
• `GROUPING SETS`는 그룹화 기준을 명시적으로 지정하여 원하는 그룹화 조합만 수행할 수 있습니다.
• `GROUPING SETS((상품ID, 월))`는 `상품ID`와 `월`의 조합으로만 그룹화합니다.
• 즉, `상품ID`와 `월`의 각 조합에 대해 매출액(`SUM(매출액)`)을 계산합니다.
2. WHERE 절:
• `월 BETWEEN '2014.10' AND '2014.12'` 조건에 따라 2014년 10월부터 12월까지의 데이터만 필터링됩니다.
3. GROUP BY 효과:
• 각 `(상품ID, 월)` 조합별로 매출액이 집계됩니다.
• 다른 그룹화 조합(예: 전체 합계, 상품ID별 합계 등)은 포함되지 않습니다.

제4절 윈도우 함수
1. WINDOW FUNCTION 을 사용하지 않고 아래의 실행 결과를 출력하는 SQL로 가장 적절한 것은?
[일자별 매출]
| 일자 | 매출액 |
| 2015.11.01 | 1000 |
| 2015.11.02 | 1000 |
| 2015.11.03 | 1000 |
| 2015.11.04 | 1000 |
| 2015.11.05 | 1000 |
| 2015.11.06 | 1000 |
| 2015.11.07 | 1000 |
| 2015.11.08 | 1000 |
| 2015.11.09 | 1000 |
| 2015.11.10 | 1000 |
[실행 결과]
| 일자 | 누적 매출액 |
| 2015.11.01 | 1000 |
| 2015.11.02 | 2000 |
| 2015.11.03 | 3000 |
| 2015.11.04 | 4000 |
| 2015.11.05 | 5000 |
| 2015.11.06 | 6000 |
| 2015.11.07 | 7000 |
| 2015.11.08 | 8000 |
| 2015.11.09 | 9000 |
| 2015.11.10 | 10000 |
1.
SELECT A.일자, SUM(A.매출액) as 누적매출액
FROM 일자별매출 A
GROUP BY A.일자
ORDER BY A.일자
2.
SELECT B.일자, SUM(A.매출액) as 누적매출액
FROM 일자별매출 A JOIN 일자별매출 B ON (A.일자 >= B.일자)
GROUP BY A.일자
ORDER BY A.일자
3.
SELECT A.일자, SUM(A.매출액) as 누적매출액
FROM 일자별매출 A JOIN 일자별매출 B ON (A.일자 >= B.일자)
GROUP BY A.일자
ORDER BY A.일자
4.
SELECT A.일자,
(SELECT SUM(B.매출액)
FROM 일자별매출 B
WHERE B.일자 >= A.일자) as 누적매출액
FROM 일자별매출 A
GROUP BY A.일자
ORDER BY A.일자• 쿼리 구조는 2번 쿼리와 유사하지만, `GROUP BY` 기준이 `A의 일자`로 설정되어 있습니다.
RANK 함수는 ORDER BY를 포함한 QUERY 문에서 특정 항목(칼럼)에 대한 순위를 구하는 함수이며 동일한 값에 대해서는 동일한 순위를 부여한다.
DENSE_RANK 함수는 RANK 함수와 흡사하나, 동일한 순위를 하나의 건수로 취급하는 것이 다른 점이다.
ROW_NUMBER 함수는 RANK나 DENSE_RANK 함수가 동일한 값에 대해서는 동일한 순위를 부여하는데 반해, 동일한 값이라도 고유한 순위를 부여한다.
2. 아래 SQL에 대한 설명으로 가장 적절한 것은?
SELECT 상품분류코드,
AVG(상품가격) as 상품가격,
COUNT(*) OVER(ORDER BY AVG(상품가격)
RANGE BETWEEN 10000 PRECEDING
AND 10000 FOLLOWING) as 유사개수
FROM 상품
GROUP BY 상품분류코드;- WINDOW FUNCTION을 GROUP BY절과 함께 사용하였으므로 위의 SQL은 오류가 발생한다.
- WINDOW FUNCTIONdml ORDER BY절에 AVG 집계 함수를 사용하였으므로 위의 SQL은 오류가 발생한다.
- 유사개수 칼럼은 상품분류코드별 평균상품가격을 서로 비교하여 -10000 ~ +10000 사이에 존재하는 상품분류코드의 개수를 구한 것이다.
- 유사개수 칼럼은 상품전체의 평균상품가격을 서로 비교하여 -10000 ~ +10000 사이에 존재하는 상품의 개수를 구한 것이다.
1. GROUP BY:
• `상품분류코드`별로 데이터를 그룹화하고, 각 그룹에 대해 `AVG(상품가격)`을 계산합니다.
2. WINDOW FUNCTION:
• `COUNT(*) OVER (...)`는 윈도우 함수로, 그룹화된 데이터에 대해 추가적인 계산을 수행합니다.
• `ORDER BY AVG(상품가격)`은 그룹화된 각 `상품분류코드`의 평균 상품 가격을 기준으로 정렬합니다.
• `RANGE BETWEEN 10000 PRECEDING AND 10000 FOLLOWING`은 현재 행의 평균 상품 가격을 기준으로 ±10,000 범위 내의 행들을 포함하여 개수를 계산합니다.
3. 결과:
• `유사개수`는 각 `상품분류코드`의 평균 상품 가격을 기준으로 ±10,000 범위 내에 존재하는 다른 `상품분류코드`의 개수를 나타냅니다.
각 항목 분석
1. “WINDOW FUNCTION을 GROUP BY절과 함께 사용하였으므로 위의 SQL은 오류가 발생한다.”
• 윈도우 함수는 GROUP BY와 함께 사용할 수 있습니다.
• GROUP BY는 데이터를 그룹화하고, 윈도우 함수는 그룹화된 결과에 대해 추가적인 계산을 수행합니다.
• 따라서 GROUP BY와 WINDOW FUNCTION이 함께 사용되더라도 오류가 발생하지 않습니다.
2. “WINDOW FUNCTION의 ORDER BY 절에 AVG 집계 함수를 사용하였으므로 위의 SQL은 오류가 발생한다.”
• 윈도우 함수의 ORDER BY 절에서 집계 함수(예: `AVG`)를 사용하는 것은 SQL 표준에서 허용되지 않습니다.
• 집계 함수는 GROUP BY 절에서 계산된 값을 반환하며, 이를 윈도우 함수의 ORDER BY 절에서 직접 사용할 수 없습니다.
• 따라서 이 SQL은 오류가 발생합니다.
3. “유사개수 칼럼은 상품분류코드별 평균상품가격을 서로 비교하여 -10000 ~ +10000 사이에 존재하는 상품분류코드의 개수를 구한 것이다.”
• SQL에서 `RANGE BETWEEN 10000 PRECEDING AND 10000 FOLLOWING`은 현재 행의 값(여기서는 평균 상품 가격)을 기준으로 ±10,000 범위 내에 있는 다른 행들을 포함하여 개수를 계산합니다.
• 이는 각 `상품분류코드`별 평균 상품 가격을 비교하여 ±10,000 범위 내에 해당하는 다른 `상품분류코드`의 개수를 구하는 것이 맞습니다.
4. “유사개수 칼럼은 상품전체의 평균상품가격을 서로 비교하여 -10000 ~ +10000 사이에 존재하는 상품의 개수를 구한 것이다.”
• 분석:
• 이 설명은 잘못되었습니다. 유사개수는 전체 상품이 아닌, 각 `상품분류코드`별 평균 상품 가격을 기준으로 ±10,000 범위를 계산한 것입니다.
추가 학습 포인트
1. 윈도우 함수와 GROUP BY:
• 윈도우 함수는 GROUP BY와 함께 사용할 수 있습니다. GROUP BY는 데이터를 그룹화하고, 윈도우 함수는 그룹화된 결과를 기준으로 추가 계산을 수행합니다.
2. 윈도우 함수에서 ORDER BY와 집계 함수 사용 제한:
• 윈도우 함수의 ORDER BY 절에서는 집계 함수를 직접 사용할 수 없습니다. 이로 인해 주어진 SQL은 오류가 발생할 가능성이 높습니다.
3. RANGE와 ROWS 차이:
• `RANGE`: 값 기반으로 범위를 지정합니다(예: ±10,000).
• `ROWS`: 물리적 행 수를 기준으로 범위를 지정합니다(예: 이전/다음 N개의 행).
제5절 Top N 쿼리
제6절 계층형 질의와 셀프 조인
1. 아래 SQL을 수행할 경우 정렬 순서상 3번째 표시될 값은?
[TAB1]
| C1 | C2 | C3 |
| 1 | NULL | A |
| 2 | 1 | B |
| 3 | 1 | C |
| 4 | 2 | D |
[SQL]
SELECT C3
FROM TAB1
START WITH C2 IS NULL
CONNECT BY PRIOR C1 = C2
ORDER SIBLINGS BY C3 DESC;- A
- B
- C
- D
CONNECT BY 절에 사용되며, 현재 읽은 칼럼을 지정한다. PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 부모 데이터에서 자식 데이터(부모 -> 자식) 방향으로 전개하는 순방향 전개를 한다. 그리고 PRIOR 부모 = 자식 형태를 사용하면 반대로 자식 데이터에서 부모 데이터(자식 -> 부모) 방향으로 전개하는 역방향 전개를 한다.
1. START WITH:
• `START WITH`는 계층 구조의 루트 노드를 정의합니다.
• 여기서는 `C2 IS NULL` 조건으로 인해 `C1 = 1`이 루트 노드가 됩니다.
2. CONNECT BY PRIOR:
• `CONNECT BY PRIOR`는 계층 구조를 정의합니다.
• `PRIOR C1 = C2` 조건으로 인해 부모 노드의 `C1` 값이 자식 노드의 `C2` 값과 일치하는 경우, 해당 노드가 연결됩니다.
3. ORDER SIBLINGS BY:
• 같은 부모를 공유하는 형제 노드들(siblings)을 특정 기준에 따라 정렬합니다.
• 여기서는 `C3 DESC`로 형제 노드들이 `C3` 값을 기준으로 내림차순 정렬됩니다.
[계층 구조 트리]
A (C1=1)
├── C (C1=3)
└── B (C1=2)
└── D (C1=4)
[정렬된 결과]
A → C → B → D
1. 루트: `A`
2. 자식들(`C`, `B`) 내림차순 정렬: `C`, `B`
3. 자식의 자식(`D`)는 부모(`B`) 아래에 위치: `D`
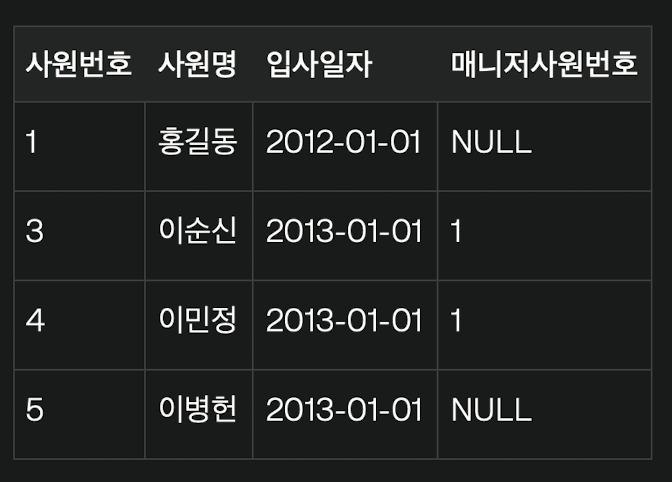
2. 아래 SQL의 실행 결과로 가장 적절한 것은?
[사원]
| 사원번호 | 사원명 | 입사일자 | 매니저사원번호 |
| 1 | 홍길동 | 2012-01-01 | NULL |
| 2 | 강감찬 | 2012-01-01 | 1 |
| 3 | 이순신 | 2013-01-01 | 1 |
| 4 | 이민정 | 2013-01-01 | 1 |
| 5 | 이병헌 | 2013-01-01 | NULL |
| 6 | 안성기 | 2014-01-01 | 5 |
| 7 | 이수근 | 2014-01-01 | 5 |
| 8 | 김병만 | 2014-01-01 | 5 |
[SQL]
SELECT 사원번호, 사원명, 입사일자, 매니저사원번호
FROM 사원
START WITH 매니저사원번호 IS NULL
CONNECT BY PRIOR 사원번호 = 매니저사원번호
AND 입사일자 BETWEEN '2013-01-01' AND '2013-12-31'
ORDER SIBLING BY 사원번호;
SQL 주요 절의 의미:
1. `START WITH 매니저사원번호 IS NULL`:
• 계층 구조의 루트 노드를 정의합니다.
• `매니저사원번호`가 `NULL`인 행이 루트가 됩니다.
• 루트 노드: `(사원번호=1, 홍길동)`과 `(사원번호=5, 이병헌)`
2. `CONNECT BY PRIOR 사원번호 = 매니저사원번호`:
• 부모 노드의 `사원번호`가 자식 노드의 `매니저사원번호`와 일치하면 계층 구조를 만듭니다.
• 예: `(사원번호=1)`이 부모 → `(매니저사원번호=1)`인 행들이 자식.
3. `AND 입사일자 BETWEEN '2013-01-01' AND '2013-12-31'`:
• 계층 구조에서 연결될 자식 노드는 `입사일자`가 `2013년`에 해당하는 경우로 제한됩니다.
4. `ORDER SIBLINGS BY 사원번호`:
• 같은 부모를 공유하는 형제 노드들을 `사원번호` 기준으로 오름차순 정렬합니다.
계층 구조 생성 과정
단계별 계층 구조:
1. 루트 노드 선택:
• `매니저사원번호 IS NULL` 조건을 만족하는 행:
• `(사원번호=1, 홍길동)`
• `(사원번호=5, 이병헌)`
2. 자식 노드 연결:
• 루트 `(사원번호=1)`의 자식 중 `입사일자 BETWEEN '2013-01-01' AND '2013-12-31'` 조건을 만족하는 행:
• `(사원번호=3, 이순신)`
• `(사원번호=4, 이민정)`
• 루트 `(사원번호=5)`는 자식이 없습니다(조건 불충족).
3. 계층형 질의문에 대한 설명으로 가장 적절하지 않은 것은?
- SQL Server에서의 계층형 질의문은 CTE(Common Table Expression)를 재귀 호출함으로써 계층 구조를 전개한다.
- SQL Server에서의 계층형 질의문은 앵커 멤버를 실행하여 기본 결과 집합을 만들고 이후 재귀 멤버를 지속적으로 실행한다.
- 오라클의 계층형 질의문에서 WHERE 절은 모든 전개를 진행한 이후 필터 조건으로서 조건을 만족하는 데이터만을 추출하는 데 활용된다.
- 오라클의 계층형 질의문에서 PRIOR 키워드는 CONNECT BY 절에만 사용할 수 있으며 'PRIOR 자식 = 부모' 형태로 사용하면 순방향 전개로 수행된다.
1. “SQL Server에서의 계층형 질의문은 CTE(Common Table Expression)를 재귀 호출함으로써 계층 구조를 전개한다.”
• 설명: SQL Server에서는 계층형 데이터를 처리하기 위해 재귀 CTE를 사용합니다. CTE는 `WITH` 키워드를 사용하여 정의되며, 앵커 멤버와 재귀 멤버로 구성됩니다. 앵커 멤버는 루트 데이터를 선택하고, 재귀 멤버는 자식 데이터를 반복적으로 검색합니다.
2. “SQL Server에서의 계층형 질의문은 앵커 멤버를 실행하여 기본 결과 집합을 만들고 이후 재귀 멤버를 지속적으로 실행한다.”
• 설명: SQL Server에서 재귀 CTE는 앵커 멤버를 먼저 실행하여 초기 결과 집합(루트 노드)을 생성한 후, 재귀 멤버를 반복 실행하여 계층 구조를 확장합니다. 이 과정은 재귀 조건이 더 이상 만족되지 않을 때까지 반복됩니다.
3. “오라클의 계층형 질의문에서 WHERE 절은 모든 전개를 진행한 이후 필터 조건으로서 조건을 만족하는 데이터만을 추출하는 데 활용된다.”
• 설명: 오라클에서는 `CONNECT BY` 절로 계층 구조를 전개하며, `WHERE` 절은 전개된 결과에서 추가적인 필터링을 수행합니다. 그러나 오라클의 계층형 질의문에서는 `CONNECT BY` 절 이전에 `WHERE` 절이 평가되지 않고, 전개 완료 후 결과에 적용됩니다.
4. “오라클의 계층형 질의문에서 PRIOR 키워드는 CONNECT BY 절에만 사용할 수 있으며 ‘PRIOR 자식 = 부모’ 형태로 사용하면 순방향 전개로 수행된다.”
• 설명: 오라클의 `PRIOR` 키워드는 부모-자식 관계를 정의하는 데 사용되며, `CONNECT BY PRIOR 자식 = 부모`는 역방향 전개(자식 → 부모)를 의미합니다. 순방향 전개(부모 → 자식)를 위해서는 `CONNECT BY PRIOR 부모 = 자식` 형태로 작성해야 합니다
4. 아래의 SQL과 실행 결과가 다른 하나는?
[테이블 생성]
CREATE TABLE T1 (NO NUMBER, COLA VARCHAR2(10));
INSET INTO T1 VALUES (1, 'AAA');
CREATE TABLE T2 (NO NUMBER, COLB VARCHAR2(10));
INSERT INTO T2 VALUES (1, 'BBB');
INSET INTO T2 VALUES (3, 'CCC');
COMMIT;
[SQL]
SELECT A.NO, A.COLA, B.COLB
FROM T1 A, T2 B
WHERE B.NO = A.NO;
1.
SELECT A.NO, A.COLA, B.COLB
FROM T1 A INNER JOIN T2 B
ON B.NO = A.NO;
2.
SELECT NO, A.COLA, B.COLB
FROM T1 A JOIN T2 B
USING (NO);
3.
SELECT A.NO, A.COLA, B.COLB
FROM T1 A CROSS JOIN T2 B;
4.
SELECT NO, A.COLA, B.COLB
FROM T1 A NATURAL JOIN T2 B;
`USING (NO)`는 두 테이블의 공통 컬럼인 `NO`를 기준으로 JOIN을 수행합니다.
제7절 PIVOT 절과 UNPIVOT 절
제8절 정규 표현식
1. GRANT와 REVOKE에 대한 설명으로 가장 적절하지 않은 것은?
- 어떤 사용자가 WITH GRANT OPTION과 함께 권한을 허가받았으면 그 사용자는 해당 권한을 WITH GRANT OPTION 유무와 관계없이 다른 사용자에게 허가할 수 있다.
- PUBLIC을 사용하면 자신에게 허가된 권한을 모든 사용자들에게 허가할 수 있다.
- REVOKE 문을 사용하여 권한을 취소하더라도 권한을 취소당한 사용자가 WITH GRANT OPTION을 통해서 다른 사용자에게 허가했던 권한들까지 연쇄적으로 모두 취소되는 것은 아니다.
- REVOKE 문을 사용하여 권한을 취소할 때 그 권한을 허가한 사용자가 권한을 취소할 수 있다.
GRANT와 REVOKE 개념
• GRANT: 데이터베이스 객체(테이블, 뷰, 프로시저 등)에 대한 권한을 사용자 또는 PUBLIC(모든 사용자)에게 부여하는 명령입니다.
• 예: `GRANT SELECT ON 테이블명 TO 사용자명;`
• WITH GRANT OPTION: 권한을 부여받은 사용자가 다른 사용자에게도 해당 권한을 부여할 수 있도록 허용합니다.
• REVOKE: GRANT로 부여된 권한을 취소하는 명령입니다.
• 예: `REVOKE SELECT ON 테이블명 FROM 사용자명;`
• 권한을 취소하면, 해당 사용자는 더 이상 해당 권한을 사용할 수 없습니다.
각 항목 분석
1. “어떤 사용자가 WITH GRANT OPTION과 함께 권한을 허가받았으면 그 사용자는 해당 권한을 WITH GRANT OPTION 유무와 관계없이 다른 사용자에게 허가할 수 있다.”
• WITH GRANT OPTION이 포함된 경우에만 권한을 다른 사용자에게 부여할 수 있습니다.
• 만약 WITH GRANT OPTION 없이 권한을 부여받았다면, 해당 사용자는 다른 사용자에게 권한을 부여할 수 없습니다.
• WITH GRANT OPTION이 없는 경우에는 다른 사용자에게 권한을 허가할 수 없으므로 틀린 설명입니다.
2. “PUBLIC을 사용하면 자신에게 허가된 권한을 모든 사용자들에게 허가할 수 있다.”
• GRANT 문에서 `TO PUBLIC`은 특정 권한을 데이터베이스의 모든 사용자에게 부여하는 것을 의미합니다.
• 예를 들어, `GRANT SELECT ON 테이블명 TO PUBLIC;`은 모든 사용자가 해당 테이블에 대해 SELECT 권한을 가지게 합니다.
3. “REVOKE 문을 사용하여 권한을 취소하더라도 권한을 취소당한 사용자가 WITH GRANT OPTION을 통해서 다른 사용자에게 허가했던 권한들까지 연쇄적으로 모두 취소되는 것은 아니다.”
• REVOKE 문으로 권한을 취소하면, 해당 사용자가 WITH GRANT OPTION으로 다른 사용자에게 부여했던 권한도 연쇄적으로 취소됩니다.
• 따라서 이 설명은 잘못되었습니다. 연쇄적인 취소는 기본 동작입니다.
4. “REVOKE 문을 사용하여 권한을 취소할 때 그 권한을 허가한 사용자가 권한을 취소할 수 있다.”
• REVOKE 문은 권한을 부여했던 사용자가 해당 권한을 취소할 수 있습니다.
• 예를 들어, A 사용자가 B 사용자에게 SELECT 권한을 부여했다면, A는 B의 SELECT 권한을 취소할 수 있습니다.
추가 학습 포인트
1. WITH GRANT OPTION의 동작:
• WITH GRANT OPTION이 있어야만 다른 사용자에게 동일한 권한을 부여할 수 있습니다.
• 이 옵션이 없다면, 다른 사용자에게 권한 부여가 불가능합니다.
2. REVOKE의 연쇄 동작:
• REVOKE로 특정 사용자의 권한이 취소되면, 그 사용자가 WITH GRANT OPTION으로 다른 사용자에게 부여했던 권한도 연쇄적으로 취소됩니다.
3. PUBLIC의 의미:
• `PUBLIC`은 데이터베이스의 모든 사용자를 의미하며, 특정 객체에 대해 공통적으로 접근 가능한 상태를 만듭니다.
2. B_User가 아래의 작업을 수행할 수 있도록 권한을 부여하는 DCL로 가장 적절한 것은?
UPDATE A_USER.TB_A
SET COL1 = 'AAA'
WHERE COL2 = 3- GRANT SELECT, UPDATE TO B_USER
- REVOKE SELECT ON A_USER.TB_A FROM B_USER
- DENY UPDATE ON A_USER.TB_A TO B_USER
- GRANT SELECT, UPDATE ON A_USER.TB_A TO B_USER
1. `GRANT SELECT, UPDATE TO B_USER`
• 이 명령은 `SELECT`와 `UPDATE` 권한을 부여하지만, 테이블 이름이 명시되지 않았습니다.
• 테이블 이름 없이 권한을 부여할 수 없으므로 이 명령은 잘못되었습니다.
2. `REVOKE SELECT ON A_USER.TB_A FROM B_USER`
• 이 명령은 `SELECT` 권한을 회수하는 명령입니다.
• 그러나 문제의 요구사항은 `UPDATE` 권한을 부여하는 것이므로, 이 명령은 적합하지 않습니다.
3. `DENY UPDATE ON A_USER.TB_A TO B_USER`
• 이 명령은 `UPDATE` 권한을 명시적으로 거부하는 명령입니다.
• 문제의 요구사항은 `UPDATE` 권한을 부여하는 것이므로, 이 명령은 적합하지 않습니다.
4. `GRANT SELECT, UPDATE ON A_USER.TB_A TO B_USER`
• 이 명령은 `A_USER.TB_A` 테이블에 대해 `SELECT`와 `UPDATE` 권한을 B_USER에게 부여합니다.
• 문제의 요구사항인 `UPDATE` 작업 수행 권한을 정확히 충족합니다.
3. 아래는 EMPLOYEE 스키마뿐만 아니라 연관된 객체들도 모두 삭제하는 SQL 명령어이다. 빈칸 ㄱ에 들어갈 내용으로 가장 적절한 것은?
DROP SCHEMA EMPLOYEE ㄱ- NULL
- NOT NULL
- CASCADE
- RESTRICT
주요 특징:
• DROP SCHEMA: 데이터베이스에서 특정 스키마를 삭제하는 명령어입니다.
• 옵션:
• `CASCADE`: 스키마와 연관된 모든 객체(테이블, 뷰, 함수 등)를 함께 삭제합니다.
• `RESTRICT`: 스키마에 연관된 객체가 존재하면 삭제를 제한합니다(기본 동작).
옵션 설명
1. CASCADE:
• 스키마 내부의 모든 객체(테이블, 뷰, 함수 등)를 포함하여 스키마를 삭제합니다.
• 이 옵션은 스키마와 관련된 객체들을 자동으로 제거하므로, 연관된 객체들도 모두 삭제해야 할 때 사용됩니다.
2. RESTRICT:
• 스키마 내부에 객체가 존재하면 스키마 삭제를 제한합니다.
• 기본 동작이며, 안전하게 스키마를 삭제할 때 사용됩니다.
추가 학습 포인트
1. CASCADE와 RESTRICT 차이점:
• `CASCADE`: 스키마와 연관된 모든 객체를 함께 삭제.
• `RESTRICT`: 스키마에 연관된 객체가 있으면 삭제 제한.
2. DROP SCHEMA의 주의점:
• `CASCADE` 옵션은 매우 파괴적이며, 모든 객체를 삭제하므로 신중히 사용해야 합니다.
• 테스트 환경에서 먼저 실행해보는 것이 권장됩니다.
3. 스키마 관리 명령어:
• 스키마 생성: `CREATE SCHEMA schema_name;`
• 스키마 변경: `ALTER SCHEMA schema_name ...;`
• 스키마 삭제: `DROP SCHEMA schema_name CASCADE | RESTRICT;`
'[자격증] > SQLD' 카테고리의 다른 글
| [오답 풀이] 1과목 (0) | 2025.03.06 |
|---|---|
| [2과목] 관리 구문 (0) | 2025.03.03 |
| [2과목] SQL 기본 (0) | 2025.03.01 |
| [1과목] 데이터 모델과 SQL (0) | 2025.02.26 |
| [1과목] 1장 데이터 모델링의 이해 (0) | 2025.02.25 |



