≣ 목차
FACTS(사실, 객관) : 이번 일주일 동안 있었던 일, 내가 한 일
SQL 공부
SQL 세션 5회차 및 내일배움캠프에서 제공한 강의를 완강했다. 새로 익힌 사실들을 정리해보자.
- JOIN과 UNION
- UNION
- 유니온은 세로로 결합한다.
- 결합할 모든 칼럼은 성격, 형식이 일치해야 한다. 컬럼의 명칭은 달라도 된다.
- 두 개 이상의 테이블도 결합할 수 있다.
- 컬럼의 순서는 같아야 한다.
- 두 테이블의 총 컬럼의 수가 달라도, 불러온 컬럼의 수가 같으면 가능하다.
- UNION은 중복되는 데이터를 제거한다.
- UNION ALL은 중복되는 데이터를 모두 표기한다.
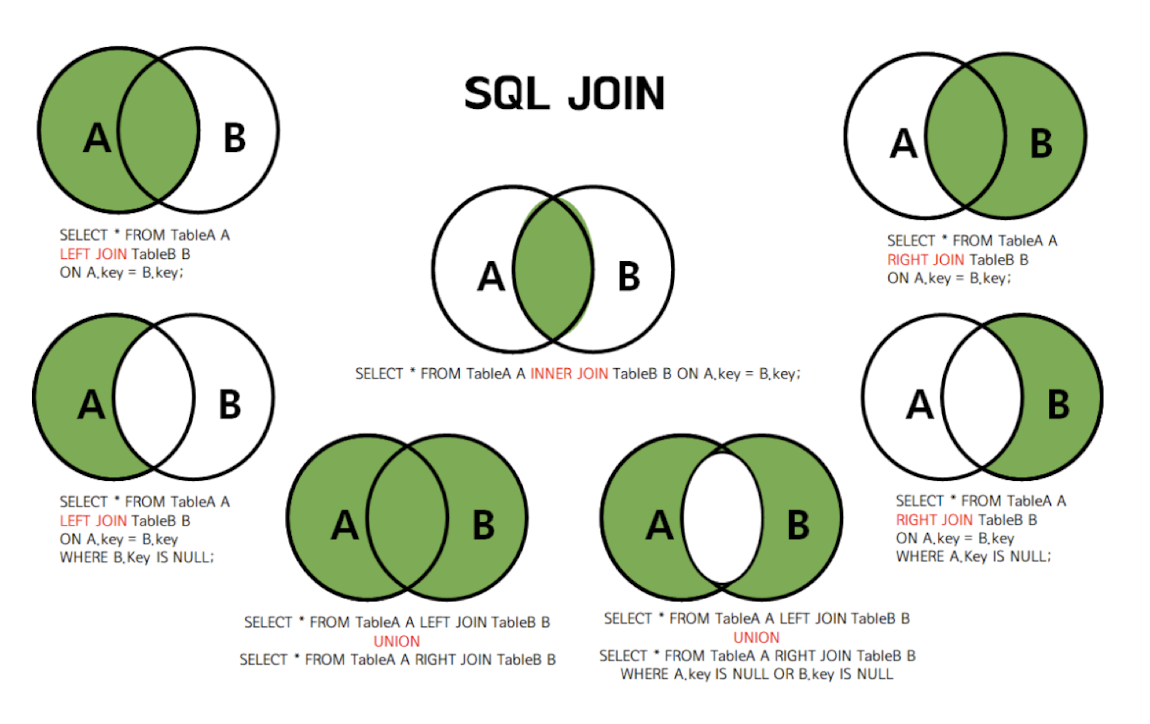
- JOIN
- 공통 컬럼이 있어야 한다. 공통 컬럼이 없다면 조인을 할 수 없다.
- 공통 컬럼 중 PK가 기준이며, FK가 따라 붙는다.
- 조인은 여러 개가 가능하다.
- 공통 컬럼이 꼭 select 절 뒤에 위치해야 하는 것은 아니다.
- PK: 기본키라고 부르며, NULL일 수 없다. 유일한 값을 가진다. 모든 컬럼의 기준이 되는 컬럼. 1:1 대응. 테이블 당 하나의 기본키(컬럼)만 가질 수 있음
- FK: 외래키라고 부르며, 연결 컬럼의 역할을 함. PK와 연결되어 테이블 간 관계를 나타냄.
- ERD(Entity Relationship Diagram): 관계도
- Mapping Cardinality
- INNER JOIN: 두 테이블에서 일치하는 값을 가진 행을 출력(교집합)
- LEFT JOIN: 왼쪽 테이블의 모든 행과 오른쪽 테이블의 일치하는 행을 반환. 일치하는 값이 없으면 오른쪽 테이블은 NULL 값을 출력함
- 참고 이미지(하단)
- UNION



- SQL이 내부적으로 인지하고 작동하는 순서
- FROM - ON - JOIN - WHERE - GROUP BY - HAVING - SELECT - DISTINCT - ORDER BY
EDA 팀프로젝트
시카고에서 운영하는 공유 자전거 서비스 Divvy에 대해 EDA 하는 팀프로젝트를 준비했다. EDA(Exploratory Data Analysis, 탐색적 데이터 분석)는 벨연구소의 수학자 ‘존 튜키’가 개발한 데이터분석 과정에 대한 개념으로, 데이터를 분석하고 결과를 내는 과정에 있어서 지속적으로 해당 데이터에 대한 ‘탐색과 이해’를 기본으로 가져야 한다는 것을 의미한다.
[데이터분석 기초] EDA의 개념과 데이터분석 잘 하는 법
오늘 포스팅 주제는 ‘데이터분석 기본 — EDA(Exploratory Data Analysis, 탐색적 데이터 분석)에 관하여 #데이터전처리 #결측치 #pandas’ 이다.
jalynne-kim.medium.com
해당 링크에서 EDA를 하는 법이 잘 적혀 있다. 하지만 나는 방향을 잘못 설계하고 데이터의 이해에서 조금 더 벗어나 자료를 준비했다. 소회는 느낌, 주관 목차에서 작성한다.
ADsP 자격증 시작
11월 3일 자격증 시험을 준비하기 위해 책을 구매, 강의를 시청한다. 현재 2일차. 새로 배운 사실은,
- DIKW 피라미드: 데이터 - 정보 - 지식 - 지혜
- 데이터의 표기법 : 바이트 - 킬로 - 메가 - 기가 - 테라 - 페타 - 엑사 - 제타 - 요타
- 암묵지와 형식지 : 공통화 - 표출화 - 연결화 - 내면화
- 데이터베이스의 특징 : 통합된 데이터 - 저장된 데이터 - 공용 데이터 - 변화되는 데이터(공통저변)
FEELINGS(느낌, 주관) : 나의 감정적인 반응, 느낌
EDA의 정의도 모르고 달려들었다
EDA를 잘 하려면, 아래 3가지 정도의 기술이 필요하다. 하지만 찾아보지 않고 무작정 달려들었다.
- raw data의 description, dictionary를 통해 데이터의 각 컬럼과 행의 의미를 이해하는 기술
- 결측치 처리 및 데이터필터링 기술
- 시각화 기술
나보다 ai가 잘 정리해줬네
FINDINGS(배운 것) : 그 상황으로부터 내가 배운 것, 얻은 것
EDA의 중요성
- 데이터 이해: EDA는 데이터 세트의 구조와 특성을 이해하는 데 도움을 줍니다. 이를 통해 적절한 분석 방법을 선택할 수 있습니다
- 이상치 및 결측치 탐지: EDA는 분석 결과에 영향을 미칠 수 있는 오류나 이상치를 식별하는 데 필수적입니다
- 가설 검증: 데이터가 특정 통계적 가정을 충족하는지 확인하여 모델링의 타당성을 평가합니다
- 패턴 및 관계 식별: 시각화와 통계 요약을 통해 변수 간의 관계와 패턴을 발견할 수 있습니다. 이는 모델링과 특징 엔지니어링에 유용한 정보를 제공합니다
EDA의 주요 단계
- 문제 이해 및 데이터 수집: 분석할 문제와 관련된 데이터를 수집하고, 변수 및 데이터 타입을 파악합니다
- 데이터 탐색 및 시각화: 데이터를 시각적으로 표현하여 패턴과 관계를 파악합니다. 히스토그램, 상자 그림, 산점도 등을 사용합니다결과
- 공유 및 문서화: 분석 결과를 이해하기 쉽게 공유하고 문서화합니다
- 특징 엔지니어링: 모델링에 필요한 새로운 특징을 생성하거나 기존 데이터를 변환합니다.
- 데이터 정제: 결측치와 이상치를 처리하여 데이터를 정리합니다
EDA의 종류
- 단변량 분석(Univariate Analysis): 하나의 변수만을 분석하여 그 분포와 특성을 파악합니다
- 이변량 분석(Bivariate Analysis): 두 변수 간의 관계를 분석하여 상관관계나 인과관계를 탐색합니다
- 다변량 분석(Multivariate Analysis): 두 개 이상의 변수 간의 복잡한 상호작용을 분석합니다
데이터 시각화
- 히스토그램 및 박스 플롯: 히스토그램은 데이터의 분포를 시각화하는 데 유용하며, 박스 플롯은 이상치와 데이터의 분포를 한눈에 파악할 수 있게 해줍니다
- 산점도 및 히트맵: 변수 간의 관계를 시각적으로 탐색할 수 있으며, 히트맵은 상관관계를 직관적으로 보여줍니다
주요 시각화 기법
- 히스토그램(Histogram): 히스토그램은 수치형 변수의 분포를 파악하는 데 사용됩니다. 데이터가 특정 값에 집중되어 있는지, 대칭적인지, 또는 이상치가 있는지를 확인할 수 있습니다. 히스토그램을 통해 데이터의 분포 패턴을 직관적으로 이해할 수 있습니다누적 분포 함수(Cumulative Distribution Function, CDF): CDF는 어떤 값보다 작거나 같은 확률을 나타내는 함수로, 데이터의 분포를 시각화하는 데 사용됩니다. 이를 통해 특정 값 이하의 확률을 추정할 수 있습니다
- 산점도(Scatter Plot): 산점도는 두 수치형 변수 간의 관계를 시각적으로 표현합니다. 상관관계를 확인하고, 두 변수 사이의 선형적 또는 비선형적 패턴을 파악할 수 있습니다
- 상자수염그림(Box Plot): 상자수염그림은 데이터의 중앙값, 사분위수, 이상치를 시각적으로 나타냅니다. 이는 범주형 변수에 따라 수치형 변수의 분포를 비교하는 데 유용하며, 데이터의 중앙 경향과 분포의 범위를 한눈에 보여줍니다
이상치를 찾는 통계적 방법
- IQR(Interquartile Range) 방법: IQR은 데이터의 중간 50% 범위를 나타내며, Q1−1.5×IQR보다 작거나 Q3+1.5×IQR보다 큰 데이터 포인트는 이상치로 간주됩니다. 이 방법은 데이터 분포에 관계없이 적용할 수 있어 유연합니다
- Z-점수(Z-score) 방법: Z-점수는 데이터 포인트가 평균으로부터 몇 표준편차 떨어져 있는지를 나타냅니다. 일반적으로 Z-점수가 3을 초과하거나 -3 미만인 데이터 포인트는 이상치로 간주됩니다. 이 방법은 데이터가 정규 분포를 따를 때 특히 유용합니다
변수 간 관계 분석
- 상관 행렬(Correlation Matrix): 여러 변수 간의 상관관계를 한눈에 파악할 수 있도록 상관 행렬을 계산하고 시각화합니다. 이는 변수 간의 연관성을 이해하는 데 유용합니다
- 피어슨 상관계수(Pearson Correlation Coefficient): 두 변수 간의 선형 관계를 측정하여 강한 상관관계를 갖는 변수 쌍을 식별합니다
출처: 퍼플렉시티: EDA란?
EDA에 대해 알려줘
Exploratory Data Analysis (EDA), 또는 탐색적 데이터 분석,은 데이터 과학 프로젝트의 초기 단계에서 수행되는 중요한 과정입니다. EDA는 데이터를 다양한 각도에서 분석하고 시각화하여 데이터의 주요
www.perplexity.ai
FUTURE(미래) : 배운 것을 미래에는 어떻게 적용할 지
좋은 EDA의 예시를 찾아, 배우고 익혀 데이터만으로 다양한 통계 분석 방법을 통해 문제를 해결해야 한다.
'내일배움캠프 > WIL' 카테고리의 다른 글
| [WIL] 5주차 개인 학습 주간 (1) | 2024.11.01 |
|---|---|
| [4주차] ADsP 자격증 준비, 파이썬 함수 정리 (0) | 2024.10.25 |
| [3주차] SQL과 파이썬, ADsP (0) | 2024.10.18 |


