참고
https://www.kaggle.com/code/joshuaswords/netflix-data-visualization/notebook
Netflix Data Visualization
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
라이브러리 호출
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans, AffinityPropagation
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import plotly as py
import plotly.graph_objs as go
import os
py.offline.init_notebook_mode(connected = True)
import datetime as dt
import missingno as msno
plt.rcParams['figure.dpi'] = 200
결측값 처리


- 결측값 비율 확인
def missing_per(df):
null_data = [] # 빈 리스트로 시작하여 각 컬럼의 결측값 정보를 저장합니다.
for col in df.columns:
null_rate = df[col].isna().sum() / len(df) * 100
if null_rate > 0:
print('{} null rate: {}%'.format(col, round(null_rate, 2)))
# null_data에 딕셔너리 형태로 추가
null_data.append({'column': col, 'null_rate': null_rate})
# DataFrame 생성
df_null = pd.DataFrame(null_data)
# 막대 그래프 생성
plt.figure(figsize=(10, 6))
plt.bar(df_null['column'], df_null['null_rate'], color='skyblue')
# 그래프 꾸미기
plt.title('Null Rate by Column', fontsize=16)
plt.xlabel('Column', fontsize=14)
plt.ylabel('Null Rate (%)', fontsize=14)
plt.xticks(rotation=45)
plt.ylim(0, max(df_null['null_rate']) + 5) # Y축 범위 설정
# 각 막대 위에 비율 표시
for index, value in enumerate(df_null['null_rate']):
plt.text(index, value + 0.5, f'{round(value, 2)}%', ha='center', va='bottom')
plt.tight_layout()
plt.show()
missing_per(df)
director null rate: 30.68%
cast null rate: 9.22%
country null rate: 6.51%
date_added null rate: 0.13%
rating null rate: 0.09%

- 대체
# 최빈값 대체
df['country'] = df['country'].fillna(df['country'].mode()[0])
# 문자 대체
df['cast'].replace(np.nan, 'No Data', inplace=True)
df['director'].replace(np.nan, 'No Data', inplace=True)
# 삭제
df.dropna(inplace=True)
# 중복 행 삭제
df.drop_duplicates(inplace=True)
- 날짜형 변환
# 공백 제거
df['date_added'] = df['date_added'].str.strip()
# 날짜형 변환
df['date_added'] = pd.to_datetime(df['date_added'])
df['month_added'] = df['date_added'].dt.month
df['month_name_added'] = df['date_added'].dt.month_name()
df['year_added'] = df['date_added'].dt.year
df.head()
- 넷플릭스 브랜드 컬러 사용
# pallette
sns.palplot(['#221f1f', '#b20710', '#e50914','#f5f5f1'])
plt.title('Netflix brand palette', loc = 'left', fontfamily = 'serif', fontsize = 15, y = 1.2)
plt.show()
- 다양한 수 체크하기 위해 count = 1 컬럼 추가
df['count'] = 1
- value 값 변경
ratings_ages = {
'TV-PG': 'Older Kids',
'TV-MA': 'Adults',
'TV-Y7-FV': 'Older Kids',
'TV-Y7': 'Older Kids',
'TV-14': 'Teens',
'R': 'Adults',
'TV-Y': 'Kids',
'NR': 'Adults',
'PG-13': 'Teens',
'TV-G': 'Kids',
'PG': 'Older Kids',
'G': 'Kids',
'UR': 'Adults',
'NC-17': 'Adults'
}
df['target_ages'] = df['rating'].replace(ratings_ages)
# Genre
df['genre'] = df['listed_in'].apply(lambda x : x.replace(' ,',',').replace(', ',',').split(','))
# Reducing name length
df['first_country'].replace('United States', 'USA', inplace=True)
df['first_country'].replace('United Kingdom', 'UK',inplace=True)
df['first_country'].replace('South Korea', 'S. Korea',inplace=True)
영화와 티브이쇼 비율
- Movie & TV Show 비율
# 영화와 티브이쇼 비율
x = df.groupby(['type'])['type'].count()
y = len(df)
r = ((x/y)).round(2)
mf_ratio = pd.DataFrame(r).T
mf_ratio
def visual_distribution(df):
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import numpy as np
# 폰트 파일 경로 설정
font_path_bold = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFBold.ttf'
font_path_medium = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFMedium.ttf'
# 폰트 프로퍼티 생성
font_bold = fm.FontProperties(fname=font_path_bold)
font_medium = fm.FontProperties(fname = font_path_medium)
fig, ax = plt.subplots(1, 1, figsize=(6.5, 2.5))
ax.barh(df.index, df['Movie'],
color='#b20710', alpha=0.9, label='Male')
ax.barh(mf_ratio.index, mf_ratio['TV Show'], left=mf_ratio['Movie'],
color='#221f1f', alpha=0.9, label='Female')
ax.set_xlim(0, 1)
ax.set_xticks([])
ax.set_yticks([])
# Movie percentage annotations
for i in df.index:
ax.annotate(f"{int(df['Movie'][i]*100)}%",
xy=(df['Movie'][i]/2, i),
va='center', ha='center', fontsize=40, fontproperties=font_bold,
color='white')
ax.annotate("Movie",
xy=(df['Movie'][i]/2, -0.25),
va='center', ha='center', fontsize=15, fontproperties=font_bold,
color='white')
# TV Show percentage annotations
for i in df.index:
ax.annotate(f"{int(df['TV Show'][i]*100)}%",
xy=(df['Movie'][i]+df['TV Show'][i]/2, i),
va='center', ha='center', fontsize=40, fontproperties=font_bold,
color='white')
ax.annotate("TV Show",
xy=(df['Movie'][i]+df['TV Show'][i]/2, -0.25),
va='center', ha='center', fontsize=15, fontproperties=font_bold,
color='white')
# Title & Subtitle
fig.text(0.125, 1.03, 'Movie & TV Show distribution', fontproperties=font_bold, fontsize=15)
fig.text(0.125, 0.92, 'We see vastly more movies than TV shows on Netflix.', fontproperties=font_medium, fontsize=12)
for s in ['top', 'left', 'right', 'bottom']:
ax.spines[s].set_visible(False)
# Removing legend due to labelled plot
ax.legend().set_visible(False)
plt.show()
visual_distribution(mf_ratio)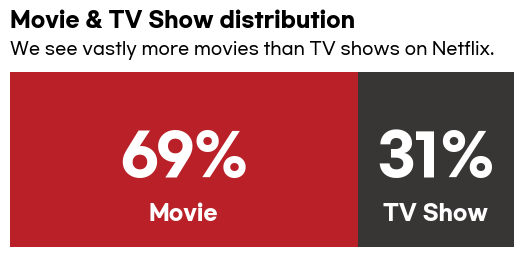
넷플릭스 TOP 10 국가 시각화
- TOP 10 국가별 count data 생성
data = df.groupby('first_country')['count'].sum().sort_values(ascending=False)[:10]
data
first_country
USA 3379
India 956
UK 576
Canada 259
Japan 235
France 196
S. Korea 194
Spain 168
Mexico 123
Turkey 106
Name: count, dtype: int64
def visual_top10(df):
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import numpy as np
# 폰트 파일 경로 설정
font_path_bold = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFBold.ttf'
font_path_medium = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFMedium.ttf'
# 폰트 프로퍼티 생성
font_bold = fm.FontProperties(fname=font_path_bold)
font_medium = fm.FontProperties(fname = font_path_medium)
# 상위 10개 국가 색상 맵 설정
color_map = ['#f5f5f1' for _ in range(10)]
color_map[0] = color_map[1] = color_map[2] = '#b20710' # 강조 색상
# 플롯 생성
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
ax.bar(x = df.index, height = df, width=0.5, edgecolor='darkgray', linewidth=0.6, color=color_map)
# 주석 추가
for i in range(len(df)):
ax.annotate(f"{df[i]}",
xy=(i, df[i] + 90),
va='center', ha='center', fontproperties=font_bold)
# 테두리 제거
for s in ['top', 'left', 'right']:
ax.spines[s].set_visible(False)
# 축 레이블 설정
ax.set_xticklabels(df.index, fontproperties=font_bold, rotation=0)
# 제목 및 부제목 추가
fig.text(0.09, 1, 'Top 10 넷플릭스 이용 국가', fontsize=15, fontproperties=font_bold)
fig.text(0.09, 0.95, '상위 세 국가 하이라이트 표시', fontsize=12, fontproperties=font_medium)
ax.grid(axis='y', linestyle='-', alpha=0.4)
grid_y_ticks = np.arange(0, 3700, 300) # y ticks 설정
ax.set_yticks(grid_y_ticks)
ax.set_axisbelow(True)
ax.set_yticklabels(ax.get_yticks(), fontproperties=font_medium, rotation=0)
plt.axhline(y=0, color='black', linewidth=1.3, alpha=.7)
ax.tick_params(axis='both', which='major', labelsize=12)
ax.tick_params(axis=u'both', which=u'both', length=0)
plt.show()
visual_top10(data)

TOP 11 국가별 Movie & TV Show 비율
- TOP 11 국가 index 추출
country_order = df['first_country'].value_counts()[:11].index
country_order
Index(['USA', 'India', 'UK', 'Canada', 'Japan', 'France', 'S. Korea', 'Spain',
'Mexico', 'Australia', 'Turkey'],
dtype='object', name='first_country')
- TOP 11 국가별, type별 value 추출
data_q2q3 = df[['type', 'first_country']].groupby('first_country')['type'].value_counts().unstack().loc[country_order]
data_q2q3
- 영화와 티브이쇼 합계 계산
data_q2q3['sum'] = data_q2q3.sum(axis=1)
data_q2q3
- 비율 계산
data_q2q3_ratio = (data_q2q3.T / data_q2q3['sum']).T[['Movie', 'TV Show']].sort_values(by = 'Movie', ascending=False)[::-1]
data_q2q3_ratio
- 시각화 함수
def visual_stacked(df):
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import numpy as np
# 폰트 파일 경로 설정
font_path_bold = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFBold.ttf'
font_path_medium = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFMedium.ttf'
# 폰트 프로퍼티 생성
font_bold = fm.FontProperties(fname=font_path_bold)
font_medium = fm.FontProperties(fname=font_path_medium)
categories = df.columns.tolist() # 모든 카테고리 열 가져오기
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
# 각 카테고리마다 막대 그래프 추가
left_position = np.zeros(len(df.index)) # 각 막대의 시작 위치
colors = ['#b20710', '#221f1f', '#FFDD44', '#44FFDD'] # 필요한 만큼 색상 추가
for idx, col in enumerate(categories):
ax.barh(df.index, df[col],
left=left_position,
color=colors[idx % len(colors)], # 색상 순환 사용
alpha=0.8, label=col)
left_position += df[col] # 다음 카테고리 시작 위치 업데이트
ax.set_xlim(0, 1)
ax.set_xticks([])
ax.set_yticklabels(df.index, fontproperties=font_medium, fontsize=10)
# 각 카테고리의 비율 주석 추가
for i in df.index:
cumulative = 0 # 누적 합계
for col in categories:
ax.annotate(f"{df[col][i]*100:.1f}%",
xy=(cumulative + df[col][i]/2, i),
va='center', ha='center', fontsize=10, fontproperties=font_medium,
color='white')
cumulative += df[col][i] # 누적 업데이트
fig.text(0.13, 0.93, 'Top 10 국가 영화와 TV 비율', fontsize=15, fontproperties=font_bold)
fig.text(0.131, 0.89, 'Percent Stacked Bar Chart', fontsize=12, fontproperties=font_medium)
for s in ['top', 'left', 'right', 'bottom']:
ax.spines[s].set_visible(False)
# 범례를 그래프 밖에 추가
ax.legend(loc = 'upper right', bbox_to_anchor=(0.97, 1.1), ncol=len(categories), prop=font_bold)
ax.tick_params(axis='both', which='major', labelsize=12)
ax.tick_params(axis=u'both', which=u'both', length=0)
plt.show()
visual_stacked(data_q2q3_ratio)
Netflix Rating count
- Groupby
order = pd.DataFrame(df.groupby('rating')['count'].sum().sort_values(ascending=False).reset_index())
order
- value 리스트화
rating_order = list(order['rating'])
rating_order
['TV-MA',
'TV-14',
'TV-PG',
'R',
'PG-13',
'TV-Y',
'TV-Y7',
'PG',
'TV-G',
'NR',
'G',
'TV-Y7-FV',
'UR',
'NC-17']
- groupby
mf = df.groupby('type')['rating'].value_counts().unstack(fill_value=0).sort_index().astype(int)[rating_order]
mf
- Movie 값 추출
movie = mf.loc['Movie']
movie
rating
TV-MA 1845
TV-14 1272
TV-PG 505
R 663
PG-13 386
TV-Y 117
TV-Y7 95
PG 247
TV-G 111
NR 79
G 39
TV-Y7-FV 5
UR 5
NC-17 3
Name: Movie, dtype: int64
- TV Show 값 추출
tv = - mf.loc['TV Show']
tv
rating
TV-MA -1016
TV-14 -656
TV-PG -299
R -2
PG-13 0
TV-Y -162
TV-Y7 -175
PG 0
TV-G -83
NR -4
G 0
TV-Y7-FV -1
UR 0
NC-17 0
Name: TV Show, dtype: int64
- 시각화
def visual_updown(data1, data2, data3):
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import numpy as np
# 폰트 파일 경로 설정
font_path_bold = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFBold.ttf'
font_path_medium = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFMedium.ttf'
# 폰트 프로퍼티 생성
font_bold = fm.FontProperties(fname=font_path_bold)
font_medium = fm.FontProperties(fname=font_path_medium)
fig, ax = plt.subplots(1,1, figsize=(12, 6))
ax.bar(data1.index, data1, width=0.5, color='#b20710', alpha=0.8, label='Movie')
ax.bar(data2.index, data2, width=0.5, color='#221f1f', alpha=0.8, label='TV Show')
#ax.set_ylim(-35, 50)
# Annotations
for i in data2.index:
ax.annotate(f"{-data2[i]}",
xy=(i, data2[i] - 60),
va = 'center', ha='center',fontproperties=font_medium,
color='#4a4a4a')
for i in data1.index:
ax.annotate(f"{data1[i]}",
xy=(i, data1[i] + 60),
va = 'center', ha='center',fontproperties=font_medium,
color='#4a4a4a')
for s in ['top', 'left', 'right', 'bottom']:
ax.spines[s].set_visible(False)
ax.set_xticklabels(data3.columns, fontproperties=font_medium)
ax.set_yticks([])
ax.legend().set_visible(False)
fig.text(0.16, 1, '영화와 티브이쇼 추천 수', fontsize=15, fontproperties=font_bold)
fig.text(0.16, 0.89,
'''We observe that some ratings are only applicable to Movies.
The most common for both Movies & TV Shows are TV-MA and TV-14.
'''
, fontsize=12, fontproperties=font_medium)
fig.text(0.755,0.924,"Movie", fontproperties=font_bold, fontsize=15, color='#b20710')
fig.text(0.815,0.924,"|", fontproperties=font_bold, fontsize=15, color='black')
fig.text(0.825,0.924,"TV Show", fontproperties=font_bold, fontsize=15, color='#221f1f')
plt.show()
visual_updown(movie, tv, mf)
연도별 콘텐츠 추가량
- Groupby
test = df.groupby(['type'])['year_added'].value_counts().sort_index().unstack(level=0, fill_value=0).astype(int)
test
- 시각화 함수
def visual_timefill(df):
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import numpy as np
# 폰트 파일 경로 설정
font_path_bold = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFBold.ttf'
font_path_medium = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFMedium.ttf'
# 폰트 프로퍼티 생성
font_bold = fm.FontProperties(fname=font_path_bold)
font_medium = fm.FontProperties(fname=font_path_medium)
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
# 색상 리스트를 확장하여 충분한 색상 제공
color = ['#b20710', '#221f1f', '#FFDD44', '#44FFDD', '#88CCEE', '#CC6677']
for i, mtv in enumerate(df.columns): # df.T.index에서 df.columns로 변경
mtv_rel = df[mtv] # 각 카테고리에 대한 데이터 가져오기
ax.plot(mtv_rel.index, mtv_rel, color=color[i % len(color)], label=mtv) # 색상 순환 사용
ax.fill_between(mtv_rel.index, 0, mtv_rel, color=color[i % len(color)], alpha=0.9)
ax.yaxis.tick_right()
ax.axhline(y=0, color='black', linewidth=1.3, alpha=.7)
for s in ['top', 'right', 'bottom', 'left']:
ax.spines[s].set_visible(False)
ax.grid(False)
ax.set_xlim(2008, 2020)
plt.xticks(np.arange(2008, 2021, 1))
fig.text(0.13, 0.85, 'Movies & TV Shows added over time', fontsize=15, fontproperties=font_bold)
ax.tick_params(axis=u'both', which=u'both', length=0)
# 범례를 그래프 왼쪽 하단에 이동
ax.legend(loc='lower left', bbox_to_anchor=(0.01, 0.15), ncol=len(df.columns), prop=font_bold)
plt.show()
visual_timefill(test)
월별 추가 콘텐츠량
- 월별 명칭 카테고리화
month_order = ['January',
'February',
'March',
'April',
'May',
'June',
'July',
'August',
'September',
'October',
'November',
'December']
df['month_name_added'] = pd.Categorical(df['month_name_added'], categories=month_order, ordered=True)
- Groupby
data_sub = df.groupby('type')['month_name_added'].value_counts().unstack(fill_value=0).loc[['TV Show', 'Movie']].cumsum(axis = 0).T
data_sub
- 시각화 함수
def visual_add(df):
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import numpy as np
import itertools
# 폰트 파일 경로 설정
font_path_bold = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFBold.ttf'
font_path_medium = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFMedium.ttf'
# 폰트 프로퍼티 생성
font_bold = fm.FontProperties(fname=font_path_bold)
font_medium = fm.FontProperties(fname=font_path_medium)
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
# 기본 색상 리스트
base_colors = ['#b20710', '#221f1f', '#FFDD44', '#44FFDD', '#88CCEE', '#CC6677']
# 컬럼 수에 맞게 색상 리스트 확장
color_cycle = itertools.cycle(base_colors)
colors = [next(color_cycle) for _ in range(len(df.columns))]
for i, mtv in enumerate(df.columns[::-1]):
mtv_rel = df[mtv]
ax.fill_between(mtv_rel.index, 0, mtv_rel, color=colors[i], label=mtv, alpha=0.9)
ax.yaxis.tick_right()
ax.axhline(y=0, color='black', linewidth=1.3, alpha=.4)
for s in ['top', 'right', 'bottom', 'left']:
ax.spines[s].set_visible(False)
ax.grid(False)
ax.set_xticklabels(df.index, fontproperties=font_medium, rotation=0)
ax.margins(x=0) # remove white spaces next to margins
fig.text(0.13, 0.95, 'Content added by month [Cumulative Total]', fontsize=15, fontproperties=font_bold)
fig.text(0.13, 0.835,
"""
The end & beginnings of each year seem to be
Netflix's preference for adding content.
""",
fontsize=12, fontproperties=font_medium)
# 범례를 그래프 밖에 추가
ax.legend(loc='upper right', bbox_to_anchor=(0.97, 1.1), ncol=len(df.columns), prop=font_bold)
ax.tick_params(axis=u'both', which=u'both', length=0)
plt.show()
visual_add(data_sub)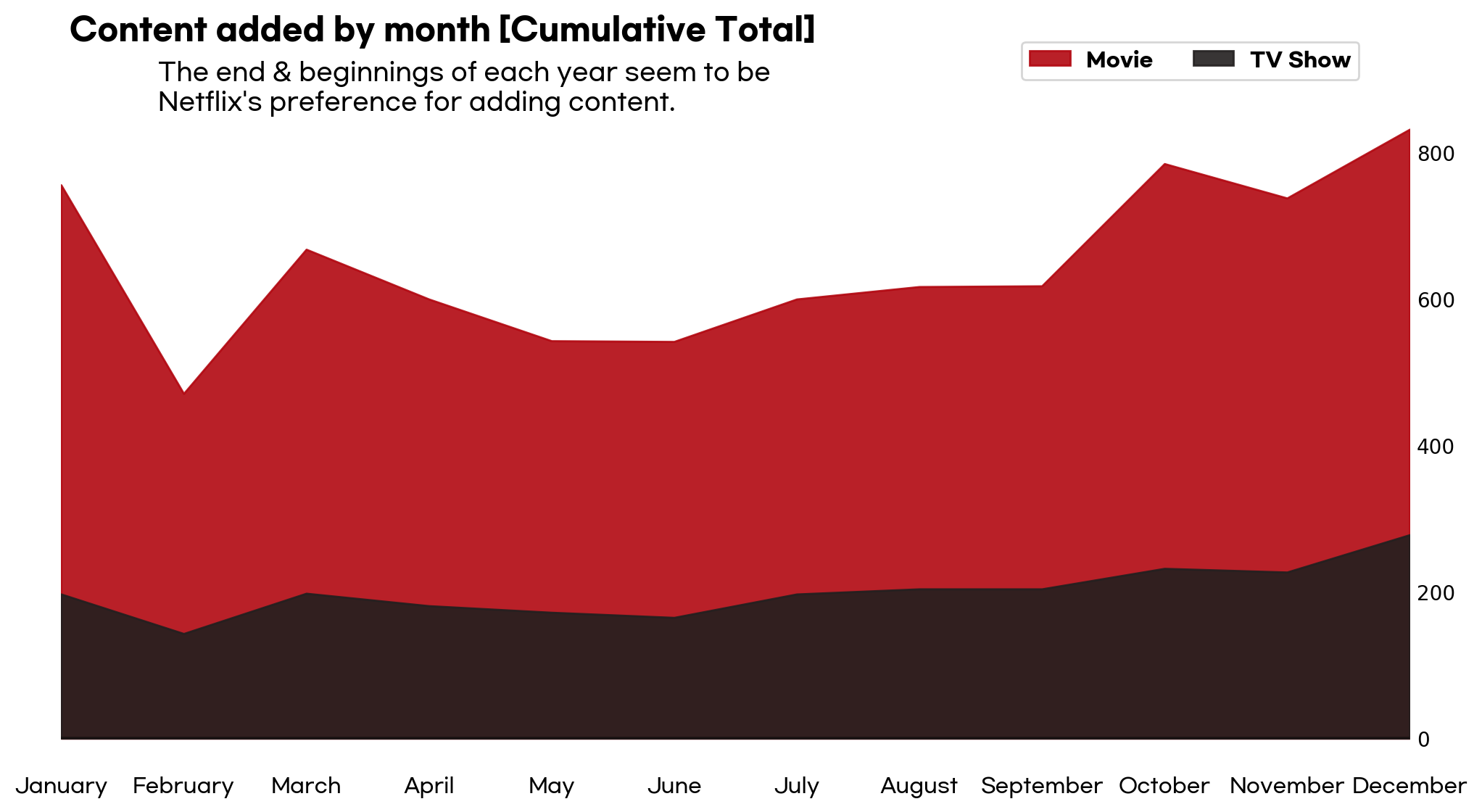
국가별 타깃 그룹 히트맵 시각화
- 상위 TOP 10 국가 추출
data = df.groupby('first_country')[['count']].sum().sort_values(by = 'count', ascending=False).reset_index()[:10]
data = data['first_country']
data
0 USA
1 India
2 UK
3 Canada
4 Japan
5 France
6 S. Korea
7 Spain
8 Mexico
9 Turkey
Name: first_country, dtype: object
- TOP 10 국가 있는 행 데이터 추출
df_heatmap_raw = df.loc[df['first_country'].isin(data)]
df_heatmap_raw.head()
- pd.crosstab 이용하여 국가별 상관관계 및 정규화 진행
df_heatmap = pd.crosstab(df_heatmap_raw['first_country'], df_heatmap_raw['target_ages'], normalize='index').T
df_heatmap
- 시각화 함수
def visual_heatmap(df):
import matplotlib.colors
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import numpy as np
cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ['#221f1f', '#b20710','#f5f5f1'])
# 폰트 파일 경로 설정
font_path_bold = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFBold.ttf'
font_path_medium = '/Users/t2023-m0089/python/6. kaggle/Visualization/GmarketSansTTFMedium.ttf'
# 폰트 프로퍼티 생성
font_bold = fm.FontProperties(fname=font_path_bold)
font_medium = fm.FontProperties(fname=font_path_medium)
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
country_order2 = ['USA', 'India', 'UK', 'Canada', 'Japan', 'France', 'S. Korea', 'Spain',
'Mexico', 'Turkey']
age_order = ['Kids','Older Kids','Teens','Adults']
sns.heatmap(df.loc[age_order,country_order2],cmap=cmap,square=True, linewidth=2.5,cbar=False,
annot=True,fmt='1.0%',vmax=.6,vmin=0.05,ax=ax,annot_kws={"fontsize":12})
ax.spines['top'].set_visible(True)
fig.text(.99, .725, 'Target ages proportion of total content by country', fontproperties=font_bold, fontsize=15,ha='right')
fig.text(0.99, 0.7, 'Here we see interesting differences between countries. Most shows in India are targeted to teens, for instance.',ha='right', fontsize=12, fontproperties=font_medium)
ax.set_yticklabels(ax.get_yticklabels(), fontproperties=font_medium, rotation = 0, fontsize=11)
ax.set_xticklabels(ax.get_xticklabels(), fontproperties=font_medium, rotation=90, fontsize=11)
ax.set_ylabel('')
ax.set_xlabel('')
ax.tick_params(axis=u'both', which=u'both',length=0)
plt.tight_layout()
plt.show()
visual_heatmap(df_heatmap)
WordCloud
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from wordcloud import WordCloud
import matplotlib.colors
# 넷플릭스 팔레트를 기반으로 한 사용자 정의 색상 맵 설정
cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ['#221f1f', '#b20710'])
# 데이터프레임의 'title' 열을 하나의 문자열로 변환하여 단어 구름 생성에 사용
text = str(list(df['title'])).replace(',', '').replace('[', '').replace("'", '').replace(']', '').replace('.', '')
# 단어 구름 모양을 정의할 마스크 이미지 불러오기
mask = np.array(Image.open('qwer.jpg'))
# 마스크 이미지 반전: 흰색 부분에 단어가 들어가도록 설정
mask = 255 - mask
# WordCloud 객체 생성 및 파라미터 설정
wordcloud = WordCloud(
background_color='white',
width=500,
height=200,
colormap=cmap,
max_words=150,
mask=mask
).generate(text)
# 단어 구름 시각화
plt.figure(figsize=(5, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off') # 축 숨기기
plt.tight_layout(pad=0)
plt.show()