파이썬으로 데이터 주무르기
https://github.com/PinkWink/DataScience
GitHub - PinkWink/DataScience: 책) 파이썬으로 데이터 주무르기 - 소스코드 및 데이터 공개
책) 파이썬으로 데이터 주무르기 - 소스코드 및 데이터 공개. Contribute to PinkWink/DataScience development by creating an account on GitHub.
github.com
https://m.yes24.com/Goods/Detail/57670268
파이썬으로 데이터 주무르기 - 예스24
독특한 예제를 통해 배우는 데이터 분석 입문이 책은 누구나 한 권 이상 가지고 있을 파이썬 기초 문법책과 같은 내용이 아닌, 데이터 분석이라는 특별한 분야에서 초보를 위해 처음부터 끝까지
m.yes24.com
목표
- 강남 3구의 체감안전도가 높다?
- 실제 안전도를 확인하기 위해 서울시 구별 범죄 발생과 그 검거율을 지표로 사용
- 데이터를 바탕으로 결론 도출
- 지도 위 시각화
1. 데이터 획득
- 공공데이터포털(https://www.data.go.kr/data/15054738/fileData.do)
- 2023년 서울경찰청 관할 경찰서별 살인, 강도, 강간 및 추행, 절도, 폭력 발생 검거 현황 (2023년 관서별 5대범죄 발생 검거 현황)

2. pandas 이용해 데이터 전처리
import numpy as np
import pandas as pd- crime_anal_police 데이터 불러오기
crime_anal_police = pd.read_csv('/Users/t2023-m0089/python/3. practice_python/python_joomooloogi/police_data/경찰청 서울특별시경찰청_경찰서별 5대범죄 발생 검거 현황_20231231.csv', thousands = ',', encoding = 'euc-kr')
crime_anal_police
- 구분이 관서별로 있어 정확하게 정리하기 위해 경찰서 목록을 소속 구별로 변경
- 지도 정보 얻을 수 있는 Google Maps API 이용
# 경찰서 이름으로 구 정보 획득
# google maps api 홈페이지 접속 후 사용자 인증 진행 후 api 키 가져오기
# 터미널 'pip install googlemaps'로 설치
import googlemaps
# API 코드 선언
gmaps_key = '(개인 API 코드)'
gmaps = googlemaps.Client(key = gmaps_key)
# geocode 불러오기
gmaps.geocode('서울중부경찰서', language = 'ko')
# 사용 데이터(전처리 및 지도 시각화에 사용)
'formatted_address': '대한민국 서울특별시 중구 퇴계로 67'
'geometry': {'location': {'lat': 37.55990389999999, 'lng': 126.9794911}
- 경찰서 이름 변경
station_name = []
for name in crime_anal_police['구분']:
station_name.append('서울' + str(name) + '경찰서')
station_name
- google maps 이용하여 주소 생성
station_address = []
station_lat = []
station_lng = []
for name in station_name:
tmp = gmaps.geocode(name, language = 'ko')
station_address.append(tmp[0].get('formatted_address'))
tmp_loc = tmp[0].get('geometry')
station_lat.append(tmp_loc['location']['lat'])
station_lng.append(tmp_loc['location']['lng'])
print(name + '-->' + tmp[0].get('formatted_address'))- station_address

- station_lat

- station_lng

- 구별 컬럼 생성
gu_name = []
for name in station_address:
tmp = name.split()
tmp_gu = [gu for gu in tmp if gu[-1] == '구']
if tmp_gu:
gu_name.append(tmp_gu[0])
else:
print(f'error: "구" not found in {name}')
gu_name.append('Unknown')
crime_anal_police['구별'] = gu_name
crime_anal_police.head()
- Unknown 확인
crime_anal_police.query('구별 == "Unknown"')
# 'Unknown'을 '동작구'로 변경
crime_anal_police.replace('Unknown', '동작구', inplace=True)
crime_anal_police.query('구별 == "동작구"')

3. pivot-table 데이터 다듬기
- 전처리 데이터 복사
crime_df = crime_anal_police.copy()
crime_df.head()- pivot-table
crime_anal_pivot = pd.pivot_table(crime_df, values = '건수', index = ['구별'], columns = ['죄종', '발생검거'], aggfunc = np.sum, fill_value = 0)
crime_anal_pivot.head()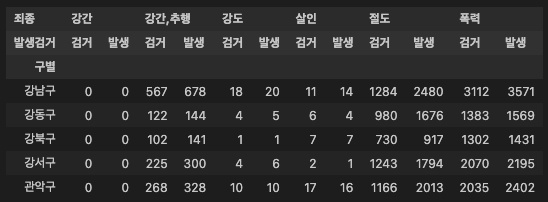
# '죄종'과 '발생검거'의 명칭을 조합하여 새로운 컬럼명 생성
crime_anal_pivot.columns = [f'{crime} {occurrence}' for (crime, occurrence) in crime_anal_pivot.columns]
crime_anal_pivot.head()

- 강간 검거, 강간 발생 다수 데이터가 0. 0이 아닌 데이터는 강간,추행 컬럼으로 이동
# 강간 발생 및 강간 검거 -> 강간,추행 발생 및 강간,추행 검거로 이동
mask = (crime_anal_pivot['강간 발생'] != 0)
data = crime_anal_pivot[mask]
data
# 설정 인덱스와 컬럼 정의
target_index = data.index
target_column = ('강간 발생')
add_column = ('강간,추행 발생')
# 설정 인덱스와 컬럼 정의1
target_index = data.index
target_column1 = ('강간 검거')
add_column1 = ('강간,추행 검거')
# 값 더하기
crime_anal_pivot.loc[target_index, add_column] += crime_anal_pivot.loc[target_index, target_column]
crime_anal_pivot.loc[target_index]
# 값 더하기1
crime_anal_pivot.loc[target_index, add_column1] += crime_anal_pivot.loc[target_index, target_column1]
crime_anal_pivot.loc[target_index]
# 강간 검거 및 강간 발생 컬럼 삭제
del crime_anal_pivot['강간 검거']
del crime_anal_pivot['강간 발생']
crime_anal_pivot.head()
- 각 검거율 계산
# 각 검거율 계산
crime_anal_pivot['강간,추행 검거율'] = crime_anal_pivot['강간,추행 검거'] / crime_anal_pivot['강간,추행 발생'] * 100
crime_anal_pivot['강도 검거율'] = crime_anal_pivot['강도 검거'] / crime_anal_pivot['강도 발생'] * 100
crime_anal_pivot['살인 검거율'] = crime_anal_pivot['살인 검거'] / crime_anal_pivot['살인 발생'] * 100
crime_anal_pivot['절도 검거율'] = crime_anal_pivot['절도 검거'] / crime_anal_pivot['절도 발생'] * 100
crime_anal_pivot['폭력 검거율'] = crime_anal_pivot['폭력 검거'] / crime_anal_pivot['폭력 발생'] * 100
crime_anal_pivot.head()
------------------------------------------
# for문을 활용한 검거율 컬럼 추가
# 각 범죄 유형을 리스트로 저장
crime_types = ['강간,추행', '강도', '살인', '절도', '폭력']
# for 문을 사용하여 각 범죄별 검거율 계산
for crime in crime_types:
crime_anal_pivot[crime + ' ' + '검거율'] = (
crime_anal_pivot[crime + ' ' + '검거'] / crime_anal_pivot[crime + ' ' + '발생'] * 100
).fillna(0) # NaN 값을 0으로 변환
# 결과 확인
crime_anal_pivot.head()
- 검거율로 검거는 알 수 있으니 각 범죄 검거 삭제
# 각 범죄 검거 삭제
del crime_anal_pivot['강간,추행 검거']
del crime_anal_pivot['강도 검거']
del crime_anal_pivot['살인 검거']
del crime_anal_pivot['절도 검거']
del crime_anal_pivot['폭력 검거']
crime_anal_pivot.head()- 이전 범죄를 검거한 경우가 있어 검거율이 100이 넘는 경우 발생. 연습이니 100으로 수정
# 검거율이 100을 초과하는 경우 100으로 설정 (clip 사용)
con_list = ['강간,추행 검거율', '강도 검거율', '살인 검거율', '절도 검거율', '폭력 검거율']
for column in con_list:
crime_anal_pivot.loc[crime_anal_pivot[column] > 100, column] = 100
crime_anal_pivot.head()
- 컬럼명에서 '발생' 삭제
crime_anal_pivot.rename(columns = {'강간,추행 발생': '강간,추행', '강도 발생': '강도', '살인 발생': '살인', '절도 발생': '절도', '폭력 발생': '폭력'}, inplace = True)
crime_anal_pivot.head()
- scikit learn에 있는 전처리(preprocessing) 도구로 정규화
# 정규화(normalize)
# scikit learn에 있는 전처리(preprocessing) 도구에 있는 최솟값, 최댓값을 이용한 정규화 함수 사용
from sklearn import preprocessing
col = ['강간,추행', '강도', '살인', '절도', '폭력']
x = crime_anal_pivot[col].values
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(x.astype(float))
crime_norm = pd.DataFrame(x_scaled, columns = col, index = crime_anal_pivot.index)
col2 = ['강간,추행 검거율', '강도 검거율', '살인 검거율', '절도 검거율', '폭력 검거율']
crime_norm[col2] = crime_anal_pivot[col2]
crime_norm.head()
- 각 범죄 및 검거 sum
col = ['강간,추행', '강도', '살인', '절도', '폭력']
crime_norm['범죄'] = np.sum(crime_norm[col], axis = 1)
crime_norm.head()
col2 = ['강간,추행 검거율', '강도 검거율', '살인 검거율', '절도 검거율', '폭력 검거율']
crime_norm['검거'] = np.sum(crime_norm[col2], axis = 1)
crime_norm.head()
4. seaborn 시각화
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
# Mac에서 한글 폰트 설정
plt.rcParams['font.family'] = 'AppleGothic'
# 마이너스 기호가 깨지지 않도록 설정
plt.rcParams['axes.unicode_minus'] = False
- pairplot으로 강도, 살인, 폭력 간 상관관계 그래프 그리기
plt.figure(figsize=(10, 6))
sns.pairplot(crime_norm, vars = ['강도', '살인', '폭력'], kind = 'reg', height = 3)
plt.show()
- Seaborn의 pairplot() 함수는 여러 변수 간의 쌍을 이루는 산점도(scatter plot)를 그려줍니다.
- vars=['강도', '살인', '폭력']: 이 옵션은 시각화할 변수 목록을 지정합니다. 여기서는 강도, 살인, 폭력 세 가지 변수를 선택했습니다.
- kind='reg': 이 옵션은 각 변수 간의 관계를 단순 산점도가 아닌 회귀선(regression line)을 포함한 그래프로 나타냅니다. 즉, 각 변수 간에 선형 회귀선을 추가하여 상관관계를 시각적으로 보여줍니다.
- height=3: 이 옵션은 각 개별 플롯의 크기를 지정합니다.
- 검거율의 합계인 검거 컬럼의 값 중 최고값을 100으로 한정하고 그 값으로 정렬
tmp_max = crime_norm['검거'].max()
crime_norm['검거'] = crime_norm['검거'] / tmp_max * 100
crime_norm_sort = crime_norm.sort_values(by = '검거', ascending=False)
crime_norm_sort.head()
- 범죄 검거 비율(정규화된 검거의 합으로 정렬)
target_col = ['강간,추행 검거율', '강도 검거율', '살인 검거율', '절도 검거율', '폭력 검거율']
plt.figure(figsize = (10, 10))
sns.heatmap(crime_norm_sort[target_col], annot = True, fmt = 'f', linewidths=.5)
plt.title('범죄 검거 비율(정규화된 검거의 합으로 정렬)')
plt.show()
- 범죄비율(정규화된 발생 건수로 정렬)
target_col = ['강간,추행', '강도', '살인', '절도', '폭력', '범죄']
crime_norm['범죄'] = crime_norm['범죄'] / 5
crime_norm_sort = crime_norm.sort_values(by = '범죄', ascending=False)
plt.figure(figsize = (10, 10))
sns.heatmap(crime_norm_sort[target_col], annot = True, fmt = 'f', linewidths=.5)
plt.title('범죄비율(정규화된 발생 건수로 정렬)')
plt.show()
5. 서울시 범죄율에 대한 지도 시각화
!pip3 install folium
# Folium 라이브러리 설치 및 불러오기
import folium
import json
geo_path = '(json 데이터, 첫 링크 참고)'
geo_str = json.load(open(geo_path, encoding = 'utf-8'))- 살인 발생 건수 지도 시각화
# 살인 발생 건수 지도 시각화
import folium
# 지도 생성
map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner',
attr='Map tiles by Stamen Design, under CC BY 3.0. Data by OpenStreetMap, under ODbL.')
# Choropleth 생성
folium.Choropleth(
geo_data=geo_str, # geo_json 데이터
data=crime_norm['살인'], # 데이터 (살인율)
columns=[crime_norm.index, crime_norm['살인']], # 인덱스와 데이터 열 지정
key_on='feature.id', # GeoJSON에서 사용할 키
fill_color='PuRd', # 색상 팔레트
fill_opacity=0.7, # 투명도
line_opacity=0.2, # 경계선 투명도
legend_name='살인 발생' # 범례 이름
).add_to(map)
# 지도 출력
map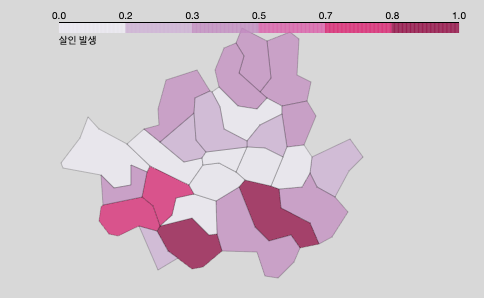
- 강간 발생 건수 지도 시각화
# 강간 발생 건수 지도 시각화
import folium
# 지도 생성
map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner',
attr='Map tiles by Stamen Design, under CC BY 3.0. Data by OpenStreetMap, under ODbL.')
# Choropleth 생성
folium.Choropleth(
geo_data=geo_str, # geo_json 데이터
data=crime_norm['강간,추행'], # 데이터
columns=[crime_norm.index, crime_norm['강간,추행']], # 인덱스와 데이터 열 지정
key_on='feature.id', # GeoJSON에서 사용할 키
fill_color='PuRd', # 색상 팔레트
fill_opacity=0.7, # 투명도
line_opacity=0.2, # 경계선 투명도
legend_name='강간,추행 발생' # 범례 이름
).add_to(map)
# 지도 출력
map
- 범죄 건수 시각화
# 범죄 건수 지도 시각화
import folium
# 지도 생성
map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner',
attr='Map tiles by Stamen Design, under CC BY 3.0. Data by OpenStreetMap, under ODbL.')
# Choropleth 생성
folium.Choropleth(
geo_data=geo_str, # geo_json 데이터
data=crime_norm['범죄'], # 데이터
columns=[crime_norm.index, crime_norm['범죄']], # 인덱스와 데이터 열 지정
key_on='feature.id', # GeoJSON에서 사용할 키
fill_color='PuRd', # 색상 팔레트
fill_opacity=0.7, # 투명도
line_opacity=0.2, # 경계선 투명도
legend_name='범죄 발생 건' # 범례 이름
).add_to(map)
# 지도 출력
map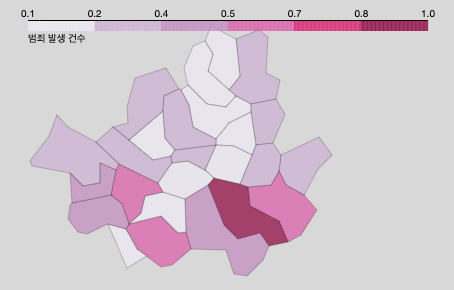
'[코드쉐도잉] > 공공데이터' 카테고리의 다른 글
| [Linear Regression] Boston Housing Data (0) | 2024.11.27 |
|---|
