가설을 먼저 정하지 않고 데이터를 탐색해보면서 가설 후보들을 찾고 데이터의 특징을 찾는 것
단계
귀무가설(H0)과 대립가설(H1) 설정
유의수준(α) 결정
검정통계량 계산
p-값과 유의수준 비교
결론 도출
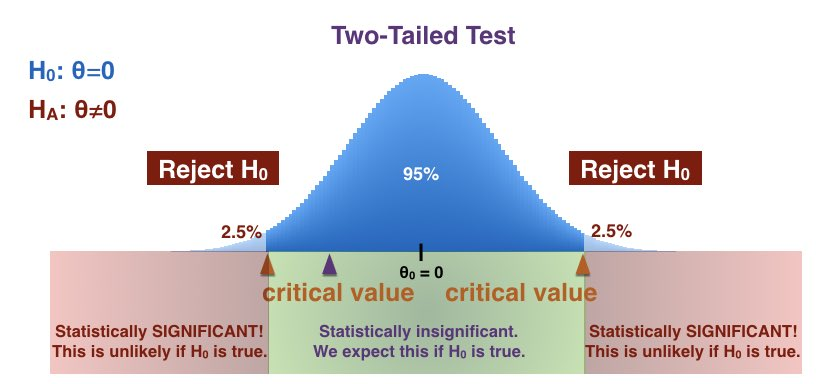
☑️ 통계적 유의성
통계적 유의성은 결과가 우연히 발생한 것이 아니라 어떤 효과가 실제로 존재함을 나타내는 지표
p값은 귀무 가설이 참일 경우 관찰된 통계치가 나올 확률을 의미
일반적으로 p값이 0.05 미만이면 결과를 통계적으로 유의하다고 판단
☑️ p-값
귀무가설이 참일 때, 관찰된 결과 이상으로 극단적인 결과가 나올 확률
일반적으로 p-값이 유의수준(α)보다 작으면 귀무가설을 기각
유의수준으로 많이 사용하는 값이 0.05
☑️ p-값을 통한 유의성 확인
p-값이 0.03이라면, 3%의 확률로 우연히 이러한 결과가 나올 수 있음
일반적으로 0.05 이하라면 유의성이 있다고 봄
☑️ 가설을 설정하여 검증
새로운 약물이 기존 약물보다 효과가 있는지 검정
이 때 새로운 약물은 기존 약물과 큰 차이가 없다는 것이 귀무가설
대립가설은 새로운 약물이 기존 약물과 대비해 효과가 있다는 것
☑️ 파이썬 실습
# 기존 약물(A)와 새로운 약물(B) 효과 데이터 생성
A = np.random.normal(50, 10, 100)
B = np.random.normal(55, 10, 100)
# 평균 효과 계산
mean_A = np.mean(A)
mean_B = np.mean(B)
# t-검정 수행
t_stat, p_value = stats.ttest_ind(A, B)
print(f"A 평균 효과: {mean_A}")
print(f"B 평균 효과: {mean_B}")
print(f"t-검정 통계량: {t_stat}")
print(f"p-값: {p_value}")
# t-검정의 p-값 확인 (위 예시에서 계산된 p-값 사용)
print(f"p-값: {p_value}")
if p_value < 0.05:
print("귀무가설을 기각합니다. 통계적으로 유의미한 차이가 있습니다.")
else:
print("귀무가설을 기각하지 않습니다. 통계적으로 유의미한 차이가 없습니다.")